Submitted by pommedeterresautee t3_10xp54e in MachineLearning
SnooHesitations8849 t1_j7tjdla wrote
A C++ implementation on CPU would be on par with python's implementation on GPU. Just mind-blowing how much you can gain from using C++. But for sure, C++ is way harder to code.
pommedeterresautee OP t1_j7tk4fx wrote
On large DL models like Whisper large, CPU is never on par with GPUs because CPU is latency oriented hardware and GPU is throughput oriented. The only ways large models are run on CPUs is by reducing the number of operations to perform like by sparsification or pruning.
Moreover, PyTorch is mostly C++ with a Python layer over it (for now at least, PyTorch 2.0 may be a start of change in this architecture). The Python layer brings most of the PyTorch latency.
And then, even C++ engine launching operations on GPU can not be on par with CUDA graphs (most of the time at least), because you have still to send instruction at a time, and there is still some latency overhead associated in running things that way, just much less than Python. With CUDA graphs there is almost none at all.There is a second thing not discussed here, it's that the graph of instructions is optimized.
Main drawback of CG is the memory overhead, you need at least to double the space taken for input tensors. On generative models with K/V cache, it matters as explained in this post. Plus you need to copy input tensors, which offsets a -very-small part of the gains (at least that s what we saw in our tests on Whisper and Bert / Roberta).
That is why TensorRT (a big C++ piece) for instance supports CUDA graphs.
Still, TBH, as you pointed out, the most important thing is that ... it's easier to build and run :-)
programmerChilli t1_j7toust wrote
> The Python layer brings most of the PyTorch latency.
This actually isn't true - I believe most of the per-operator latency come from C++.
pommedeterresautee OP t1_j7tp663 wrote
I guess you better know than me :-)
Which part? The dispatcher thing or it's spread on several steps?
programmerChilli t1_j7tpwd7 wrote
Lots of things. You can see a flamegraph here: https://horace.io/img/perf_intro/flamegraph.png (taken from https://horace.io/brrr_intro.html).
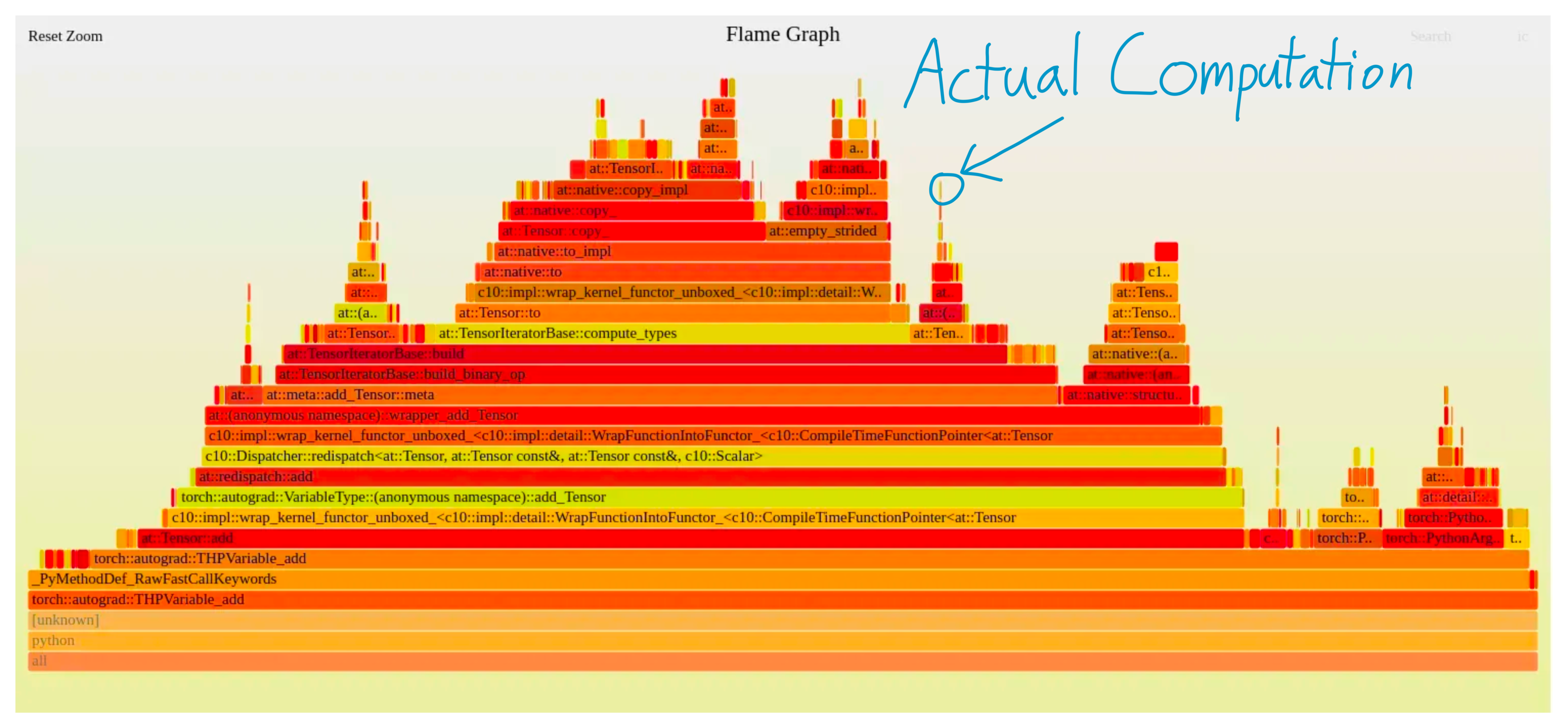{kind=link}
Dispatcher is about 1us, but there's a lot of other things that need to go on - inferring dtype, error checking, building the op, allocating output tensors, etc.
anders987 t1_j7ujo5v wrote
There already exists a C++ CPU only implementation of Whisper.
SnooHesitations8849 t1_j7uuh1w wrote
Yep. I am using it and it is really good for inference.
clauwen t1_j7txja0 wrote
You really have to wonder why everybody uses torch and tf2 then. Stupid trillion dollar companies, could just run everything on cpu, if they could only hire C++ devs. Billions of dollars down the drain, really unlucky.
Wrandraall t1_j7u76m1 wrote
Training =/= inference anyway. Whatever can be reached with CPU inference time, training still benefit by using GPUs from parallelization and caching
Viewing a single comment thread. View all comments