Submitted by Old_Scallion2173 t3_115wu59 in MachineLearning
Hello, community.
Description:
I am planning to create a detection model using YOLO v8 to detect leukemia cells in a blood sample. I started learning about deep learning two months ago and I am eager to try out image segmentation on my present dataset instead of bounding boxes, as the cells are closely bunched together. I need advice on whether I should use bounding boxes or instance segmentation, considering my dataset and expected results.
Context:
Leukemia is caused by an abundance of different types of naive or altered white blood cells in the body, which overwhelm the bloodstream and inhibit the proper functioning of normal white blood cells. There are three classes in my dataset: lymphoblasts, promyelocytes, and neutrophils, and I need to be able to detect these cells.
Expected Results:
As this is a medical domain, false positives are acceptable, but false negatives are not.
About dataset:
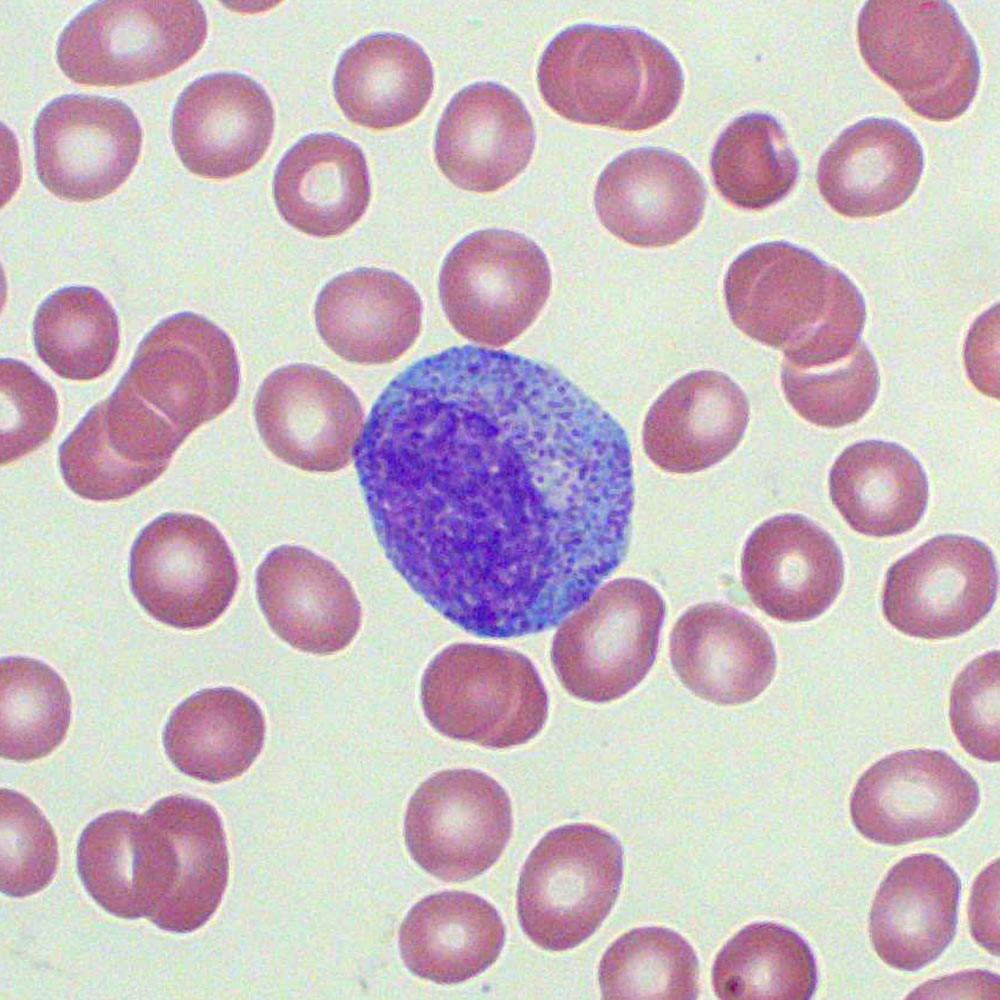
sample image for promyelocytes
{kind=link}
{kind=link}
lymphoblasts(101 images)
promyelocytes(91 images)
neutrophils(133 images)
more context for your reading:
An over abundance of lymphoblasts results in acute lymphoblastic leukemia (ALL), while acute pomyelocytic leukemia (APLML/APL) is caused by an abnormal accumulation of promyelocytes. neutrophils do not cause leukemia.
blackhole077 t1_j93xnn8 wrote
Since I'm on a mobile device I'll write a shorter answer that hopefully gives you some insight.
From what I've understood of your question, you're wanting to know if bounding boxes would perform worse due to the proximity of cells you wish to detect.
Both methods may struggle with the cells being in close proximity, and instance segmentation may perform better in that regard. However I will reframe the question slightly.
First, there's a reason that object detection and instance segmentation are different methods. The latter is preferred in situations where you need to know the pixels that are considered to be the detected class, which I think is not what you're aiming for.
Second, the annotation process is, of course, more labor intensive when you want segmentation masks. Luckily you should be able to generate bounding boxes from masks easily, but keep it in mind if you're on a tighter schedule.
If you have additional questions please let me know. I wish you luck in your endeavor.
Hope this helps