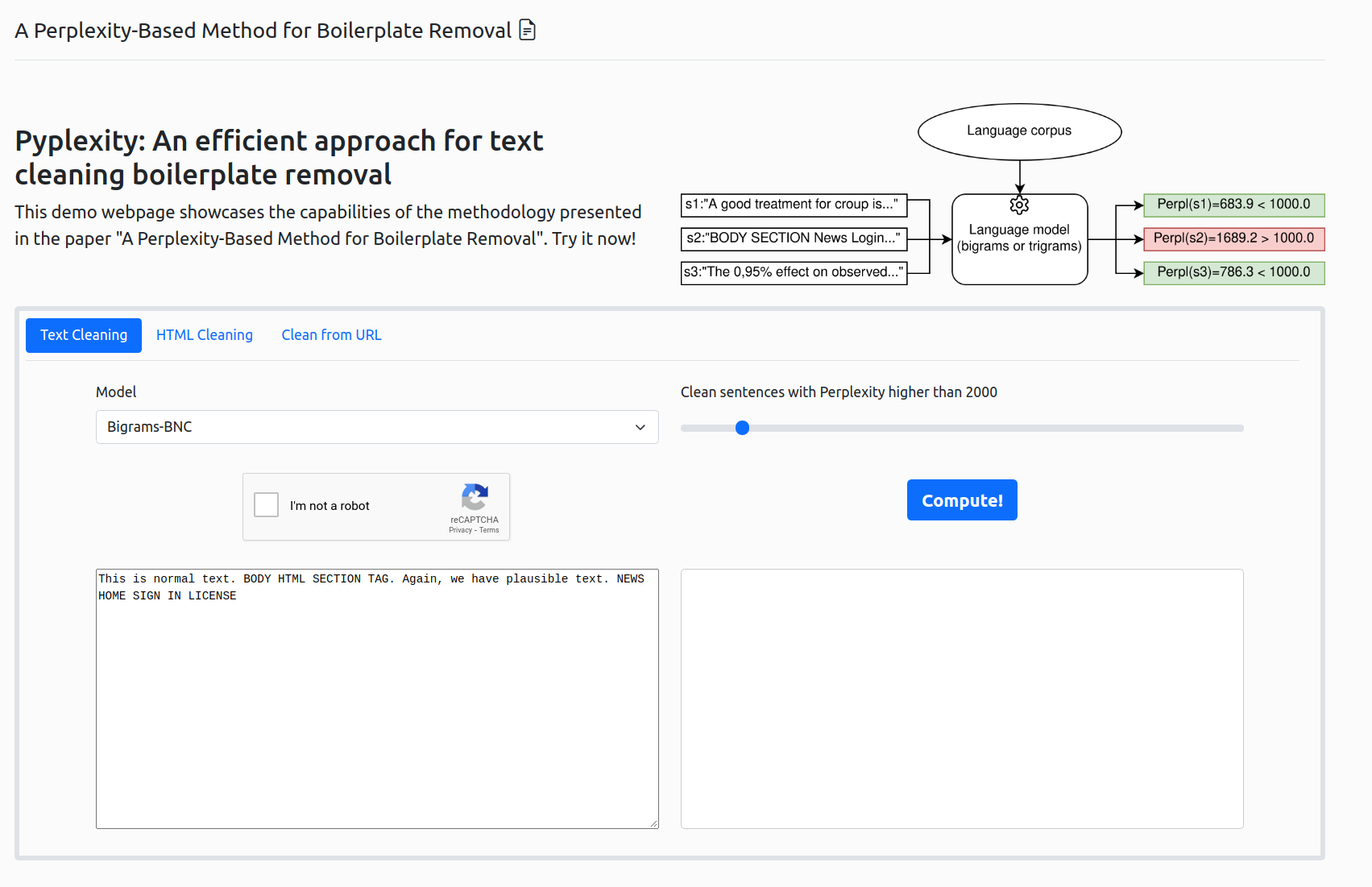
 Pyplexity: Useful tool to clean scraped text (better than BS4!)
Pyplexity: Useful tool to clean scraped text (better than BS4!)Submitted by usc-ur t3_11r45r8 in coolgithubprojects
usc-ur OP t1_jca4ot7 wrote
Reply to comment by Aphix in Pyplexity: Useful tool to clean scraped text (better than BS4!) by usc-ur
Sure! The idea is that you create a language model from a given corpus (let's say BNC) and then you use a similarity measure, in this case, perplexity, but can be another one to test how well your sample (sentence) "fits" into the model distribution. Since we assume the distribution is correct, this allows us to identified malformed sentences. You can also check the paper here: https://www.cambridge.org/core/journals/natural-language-engineering/article/an-unsupervised-perplexitybased-method-for-boilerplate-removal/5E589D838F1D1E0736B4F52001150339#article
Viewing a single comment thread. View all comments