Comments
mikeholczer t1_j6agh1p wrote
Following those rules the most likely outcome is “A”
kilopeter OP t1_j6b6t8c wrote
Yep. "A" is the most frequent letter at both the start and end of names in the dataset I used (girls born in 2021 in the USA).
mikeholczer t1_j6b7fim wrote
My point is your interpretation is flawed, because the most likely outcome of it is very far from the actual most likely name.
kilopeter OP t1_j6b9h0h wrote
Oh, absolutely: the fact that this Markov assumption yields nonsensical names shows that the sequence of letters in given names are not generated by a Markov process. (The next character depends very much on previous characters, not just the current one.)
But this visualization does accurately present the relative frequencies of character transitions in actual names. Using these frequencies to generate Markov chains of characters and calling the results names is a fun diversion whose results I found entertaining.
mikeholczer t1_j6b9was wrote
Yeah, I think the display of the data is interesting, I just think what you wrote about it is misleading.
kilopeter OP t1_j6banxn wrote
Oh? What part? I specifically qualified my interpretation with "want to reflect typical between-letter patterns of US girl names."
That's the point of using this viz to generate new names: generating character strings with totally realistic letter-to-letter transition probabilities is not enough to yield plausible names, or names which already exist. The generated names are often bizarre or excessively long, yet their character transition probabilities exactly reflect that of the real names in the input dataset.
mikeholczer t1_j6bb50x wrote
If one follows your steps, the most common outcome is one letter and there has no between-letter patterns which clearly doesn’t match the between-letter patterns of the source data.
kilopeter OP t1_j6bbmom wrote
It does if you include the placeholder "characters" for the start and end of each name! The most probable "name" A represents three tokens: [name start], A, [name end]. And if you generate many names using the transition matrix, you will indeed observe that the frequency of [name start] -> A and A -> [name end] matches the corresponding frequencies in the source data.
EDIT: on reflection, I agree with you. I should introduce the heatmap as a description of transition probabilities, but should avoid walking the reader through using the transition matrix to generate new "names." I should separate the topic of generating new names using the transition matrix under the (invalid) Markov assumption as a diversion. Thanks for pointing out the flaw in my explanation. I'll edit my top level comment when I have a chance!
globglogabgalabyeast t1_j6bwjuz wrote
Did you already edit it? Cause I never got the impression that you were implying this process would lead to realistic names
kilopeter OP t1_j6ea6zq wrote
Nah, I'm only just now getting a chance to edit my top-level comment. Thanks for throwing in your vote! I feel like I can reword the "interpretation" part better to avoid any possible misinterpretation.
ghostfaceschiller t1_j6bz394 wrote
Have you done this analysis on any other corpora? I’d be super interested to see it on something like the Google Corpus (or a reasonable subset of it). Or BNC, etc
kilopeter OP t1_j6ecjw9 wrote
I haven't, but good point. The code to count transitions between characters is very straightforward (well... I wrote mine without worrying about performance issues), and in principle could be packaged as a lightweight web app or even a JavaScript-powered static site and accept any text corpus uploaded or linked by the user.
ghostfaceschiller t1_j6ej1pw wrote
I recently put together a repo of character frequency analyses, bc they can be really useful when designing keyboard layouts. So I have an eye out rn for interesting ways to look at and visualize the data. I think this particular instance is probably too limited to be useful for keyboard layouts, but if you do anything more please let me know! It’s one of the more interesting visualizations I’ve seen so I’d love to include/link it
kilopeter OP t1_j6eq2tj wrote
Oh nice, I'll let you know!
Only-Engineering6586 t1_j6asb14 wrote
Computer Generated Girl Names, Based on this Data:
A (Most Likely)
Be
Ca
Da
E
Fia
Ga
H
Ia
Ja
Ka
Lia
Ma
Na
Oria
Pe
Quria
Ria
Sa
Tria
Uria
Via
Xiay
Y
Za
desperaste t1_j6b02jp wrote
A few of those aren’t terrible tbf
Only-Engineering6586 t1_j6b07r4 wrote
Yes! I know some Lia’s. Also, who doesn’t love a good ‘Za!?
Opening_Cartoonist53 t1_j6ebbs9 wrote
With pepperoni?
Consistent_Paper_104 t1_j6imw56 wrote
Big fan of quria personally
[deleted] t1_j6btjzn wrote
[removed]
TaqPCR t1_j6aeh8d wrote
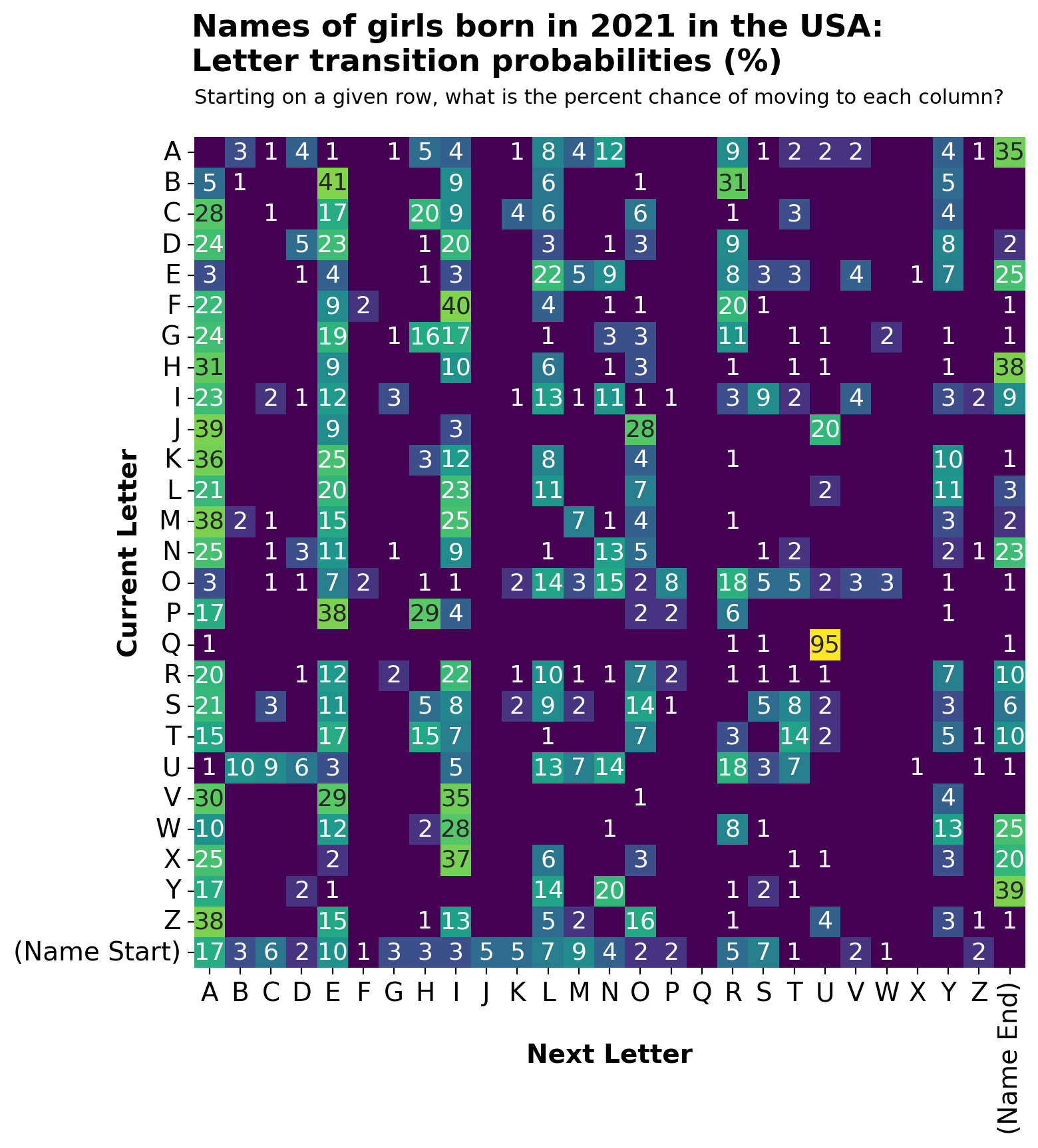
If you start at the most common letter at the beginning of the name, A, then the highest value is to immediately end the name. But if you exclude that the highest value is N which then leads to another A with probability just above that of ending the name. So in a way this chart comes close to spelling out Ana just from the data presented. The probability being .17*.12*.25*.23 = 0.1173%
coodgee33 t1_j6aft3z wrote
Q to u transition is strong.
myrianthe t1_j6bd1x9 wrote
Yup. U is the most common letter to come after Q in general, not just in names. Because interestingly there isn't really another vowel nor letter that works after Q (Qa Qe Qi Qo Qr Ql?)
Some of the more popular Q names include Quinn, Quincy, Queen/Queenie, and Quintessa.
Bored470 t1_j6cixw1 wrote
In school we learned Q is married to U
MrLagzy t1_j6cmypw wrote
Only words i can think of that doesn't have U after Q is Qatar or Qaeda.
Maybe more common in Arab languages?
myrianthe t1_j6cq469 wrote
Interesting! I haven’t thought of that.
Latin had the same Qu thing, so perhaps it’s only common among the Latinate languages.
MrLagzy t1_j6crlvl wrote
When it comes to English, Danish (I'm Danish) or Spanish i don't think there's any words originating from these languages where Q isn't followed by a U.
I tried googling Q words and all words i found where it wasn't followed by a U, was Arab surnames, Arab or asian words. Qi for an example. Albanian currency is called Qintar.
sshuggi t1_j6an6i6 wrote
I generated the names for each starting letter, and these are the (mostly trivial) names that result when only using the dominant probabilities:
A BE CA DA E FIA GA H IA JA KA LI MA NA ORIA PE QURIA RIA SA TE URIA VIA WIA XIA Y ZA
Ironically, the only one that really looks like a name, Quira, means lady in Greek. (Spelled κυρία.)
moriclanuser2000 t1_j6cwonm wrote
if you take the most popular letter that hasn't been used yet, you get:
ANELISORY
dbeats20 t1_j6acpf4 wrote
Can you explain how to interpret it?
Raveyard2409 t1_j6c3zjr wrote
I don't really see any interesting insight other than the fact that in English the letter U always follows a Q. @OP - what should we take from this visualisation?
[deleted] t1_j6ak88b wrote
[removed]
TheKrunkernaut t1_j6aocpa wrote
This all the ways spell Jasmyn?
gnomeba t1_j6etjv4 wrote
This is great. Are the probabilities conditioned on the total distribution of the letters? If not, this might make a more realistic fake name generator.
Arquen_Marille t1_j6akbuv wrote
GH and GI being the same color makes it look like 1617%.
Edit: Is Qu really that common? I also see that A as a second letter is extremely popular.
the_scign t1_j6d2no9 wrote
Number is the percentage chance of the next letter being the column letter, assuming you're already at the row letter. I.e. if you are at a "Q", there's a 95% chance the next letter will be a "U". This says nothing about the "popularity" of the letter combination by itself.
"A" as a next letter follows most consonants. Not necessarily the second letter in the name.
Arquen_Marille t1_j6hph24 wrote
Then it’s unnecessarily complicated.
rug1998 t1_j6b80wv wrote
95 names with Qu? I can’t think of one
kilopeter OP t1_j6b9oys wrote
That 95 means that 95% of the time, a Q was followed by a U in a name.
rug1998 t1_j6bc16j wrote
Bro… ok got it
myrianthe t1_j6bcix9 wrote
U is the most common letter to come after Q in general, not just in names. Because interestingly there isn't really another vowel nor letter that works after Q (Qa Qe Qi Qo Qr Ql?)
Some of the more popular Q names include Quinn, Quincy, Queen/Queenie, and Quintessa.
kismatwalla t1_j6bb15t wrote
Names are not memory-less, transition probability does not make sense.
kilopeter OP t1_j6bb7id wrote
The fact that names are not memoryless is exactly why treating them as such produces such entertaining results :)
Background_Newt_8065 t1_j6c0nud wrote
This is data but unfortunately it’s not beautiful
kilopeter OP t1_j6adleq wrote
Interpretation [EDITED]: Take all the names on U.S. Social Security card applications for girls born in 2021. Scan through the names one letter at a time, accounting for the start and end of each name. Count how many times each particular letter is followed by every other letter in the alphabet. Finally, convert your counts to probabilities (technically, percent chance = probability * 100%) to give the chance that any given letter in a name is followed by every other possible letter (or by the end of the name). This visualization summarizes the resulting transition matrix.
Background: The ongoing explosion of generative AI systems got me thinking about the statistical structure of words, and of given names in general. I started with the fairly basic idea of treating the sequence of characters in given names as a Markov process, i.e., the next state is chosen randomly according to transition probabilities that depend only on the current state, not prior states.
Code: https://github.com/pjleimbigler/baby-name-analysis
Data: https://www.ssa.gov/oact/babynames/limits.html
Generating new "names": The letters in given names are pretty clearly not generated by a Markov (memoryless) process. However, it's fun to assume the Markov property anyway and see what "names" fall out of the transition matrix.
To iterate through the transition matrix manually using this viz, follow these steps:
(Name Start).(Name End), which signifies the end of your generated name.This yields some hilarious yet often oddly plausible names, such as: Silian, Slya, Lialy, Maerollia, Chla, Zalah, Lay, Lonanaadievayle, Zoralepa, Peiemophaly, Dralesa, Wiada, Miea, Giaberosh, Bisodiaremanninenn, Seelanida, Einnn, Penasoetimala, Hepanelei, Mia, Mierolynakynisayloloneeloa, Sargandniamilida, Eldyanempe, Pinahanariloma, Alian, Melivevilllohayasisa, Olyna, Die, Mizaramiceatelyalla, Jon, Adelun, Cesklienzolena, Zolyryn, Ema, Leyla, Aclan, Bra, Maeylises, Bryn, Khiemi, Sly, Annnlis, Aisyasa, Xily, Kara, Handanaria, Manla, Pama, Heyanama, Eylisidr, Brah, Llee, Anelerynaevega, Ayatryalofa, Mediza, Caniesty, Oliceeelys, Sannllora, Dassole, Sonnasse, Mmatarieleteyneroselasylin.