 What. The. ***k. [less than 1B parameter model outperforms GPT 3.5 in science multiple choice questions]
What. The. ***k. [less than 1B parameter model outperforms GPT 3.5 in science multiple choice questions]Destiny_Knight OP t1_j9iysi7 wrote
The paper: https://arxiv.org/pdf/2302.00923.pdf
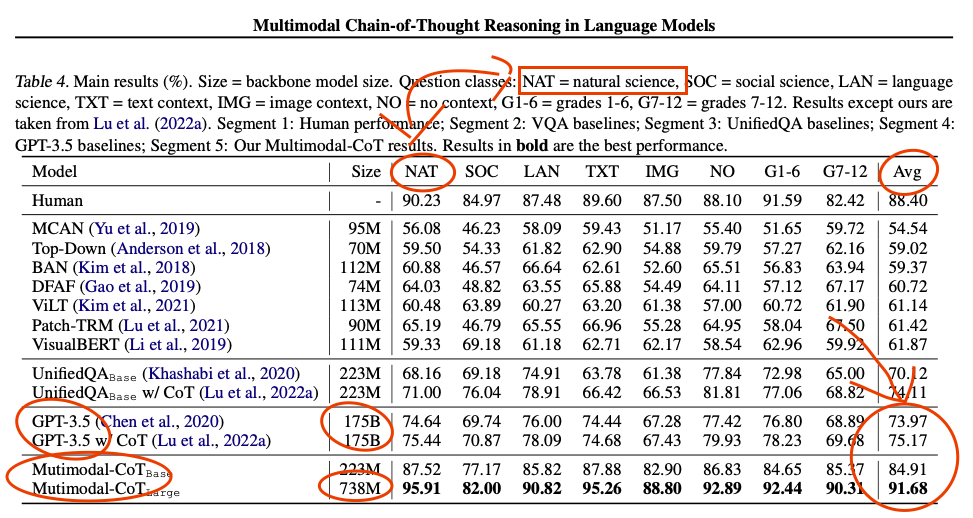
The questions: "Our method is evaluated on the ScienceQA benchmark (Lu et al., 2022a). ScienceQA is the first large-scale multimodal science question dataset that annotates the answers with de- tailed lectures and explanations. It contains 21k multimodal multiple choice questions with rich domain diversity across 3 subjects, 26 topics, 127 categories, and 379 skills. The benchmark dataset is split into training, validation, and test splits with 12726, 4241, and 4241 examples, respectively."
FirstOrderCat t1_j9ja0i4 wrote
multimodal here means questions contain pictures.
So, it is obvious gpt would underperform since it doesn't work with pictures, lol?..
EndTimer t1_j9kl706 wrote
We would have to read the study methodology to evaluate how they were testing GPT 3.5's image context.
But in this case, multimodal refers to being trained on not just text (like GPT 3.5), but also images associated with that text.
That seems to have improved their model, which requires substantially fewer parameters while scoring higher, even in text-only domains.
kermunnist t1_j9kpbtz wrote
That would make sense, having an understanding of images probably helps lead to a more intuitive grasp of physics
{kind=link}
FirstOrderCat t1_j9krjxb wrote
>which requires substantially fewer parameters while scoring higher, even in text-only domains.
Which tests in paper refer on text-only domains?
EndTimer t1_j9l1xxj wrote
Presumably, TXT (text context). LAN (language sciences) are unlikely to have many images in their multiple choice questions. The other science domains and G1-12 probably have majority text questions.
FirstOrderCat t1_j9l4bho wrote
What is IMG for GPT then there?
How come GPT performed better without seeing context compared to seeing text context?..
EndTimer t1_j9l4tc6 wrote
I don't know. It's going to be in the methodology of the paper, which neither of us have read.
FirstOrderCat t1_j9l8xn9 wrote
Yes, and then reproduce results from both papers, check the code to see nothing creative happens in datasets or during training, and there are much more claims in the academia than one has time to verify.
iamascii t1_j9o2v76 wrote
They used the captions instead of the images. The captions are pretty descriptive imho.
FirstOrderCat t1_j9p55p9 wrote
It still doesn't answer second question.
duffmanhb t1_j9jps75 wrote
So basically it's fine tuned for this specific topic, where GPT is large because it's a general dataset for multidomain use.
[deleted] t1_j9jlyhh wrote
[deleted]
Viewing a single comment thread. View all comments