Comments
turnip_burrito t1_j9j2sg5 wrote
Yes, and it does it with only 0.4% the size of GPT3, possibly enough to run on a single graphics card.
It uses language and pictures together instead of just language.
sumane12 t1_j9j3b9j wrote
Fucking wow!
turnip_burrito t1_j9j3pea wrote
Yeah it's fucking nuts.
Neurogence t1_j9jef7k wrote
What is the "catch" here? It sounds too good to be true
WithoutReason1729 t1_j9jmd05 wrote
The catch is that it only outperforms large models in a narrow domain of study. It's not a general purpose tool like the really large models. That's still impressive though.
Ken_Sanne t1_j9jxg68 wrote
Can It be fine tuned ?
WithoutReason1729 t1_j9jxy78 wrote
You can tune it to another data set and probably get good results, but you have to have a nice, high quality data set to work with.
Ago0330 t1_j9lm5ty wrote
I’m working on one that’s trained on JFK speeches and Bachlorette data to help people with conversation skills.
Gynophile t1_j9msb3s wrote
I can't tell if this is a joke or real
Ago0330 t1_j9msg1r wrote
It’s real. Gonna launch after GME moons
ihopeshelovedme t1_j9npl0j wrote
Sounds like a viable AI implementation to me. I'll be your angel investor and throw some Doge your way or something.
Borrowedshorts t1_j9ka0ta wrote
I don't think that's true, but I do believe it was finetuned on the specific dataset to achieve the SOTA result they did.
InterestingFinish932 t1_j9m2xhe wrote
It chooses the correct answer from multiple choices. it isn't actually comparable to chatGtp.
FoxlyKei t1_j9j7b6s wrote
Where can I get one? I'll take 20
Imaginary_Ad307 t1_j9jjwf6 wrote
Around 4GB vram, maybe 2GB to run it.
em_goldman t1_j9jzamt wrote
That’s so cool!! That’s how humans remember things, too
Agreeable_Bid7037 t1_j9jsc0w wrote
amazing.
gelukuMLG t1_j9kftza wrote
does that prove that parameters aren't everything?
dwarfarchist9001 t1_j9knt85 wrote
It was shown recently that for LLMs ~0.01% of parameters explain >95% of performance.
gelukuMLG t1_j9kxnj4 wrote
But higher parameters allow for broader knowledge right? You can't have a 6-20B model have broad knowledge as a 100B+ model, right?
Ambiwlans t1_j9lab3g wrote
At this point we don't really know what is bottlenecking. More params is an easyish way to capture more knowledge if you have the architecture and the $$... but there are a lot of other techniques available that increase the efficiency of the parameters.
dwarfarchist9001 t1_j9lb1wl wrote
Yes but how many parameters must you actually have to store all the knowledge you realistically need. Maybe a few billion parameters is enough to store the basics of every concept known to man and more specific details can be stored in an external file that the neural net can access with API calls.
gelukuMLG t1_j9lfp3j wrote
You mean like a LoRA?
turnip_burrito t1_j9kgb2q wrote
We already knew parameters aren't everything, or else we'd just be using really large feedforward networks for everything. Architecture, data, and other tricks matter too.
Nervous-Newt848 t1_j9qgisf wrote
Its much small enough to run on a single graphics card
[deleted] t1_j9nhlub wrote
[deleted]
soapyshinobi t1_j9jo9rw wrote
It's outperforming religion for some now.
https://www.businessinsider.com/rabbi-chat-gpt-ai-sermon-deathly-afraid-2023-2
sumane12 t1_j9jz889 wrote
Atleast AI can make accurate predictions for the next character in a line of text, which is better than any religion has predicted 🤣
gthing t1_j9kghrm wrote
Amen.
Fedude99 t1_j9ps9w4 wrote
Religion is just anything you have faith ("belief") in without understanding the belief justification chains (or even that there is such a thing as different kinds of links in belief justification chains).
Thus, modern atheists are religious as well as they don't actually understand the Science (tm) and "logic" that shapes their beliefs, and they end up in culture war battles no different from early religious wars.
Modern science can no longer even predict what a man or woman is, which is just as simple as predicting what color the sky is. As an atheist myself, it's important to acknowledge the win religion has on this one.
sumane12 t1_j9ptb8u wrote
Great post. I was about to counter that religion would require some kind of worship, but there's religions such Buddhism that requires no such worship.
IluvBsissa t1_j9pzh0q wrote
There is a lot of worship is SEA tho.
SnooHabits1237 t1_j9rglfg wrote
Whst makes you think that atheists don’t understand the logic behind their beliefs? Religion is based off of myth and atheism is evidence based and logical.
SnooHabits1237 t1_j9rgs3w wrote
Whst makes you think that atheists don’t understand the logic behind their beliefs? Religion is based off of myth and atheism is evidence based and logical.
ninjasaid13 t1_j9js0zk wrote
"ChatGPT might be really great at sounding intelligent, but the question is, can it be empathetic? And that, not yet at least, it can't," added Franklin.
He admitted there's a chance.
gthing t1_j9kgkhy wrote
It's good at faking empathy, just like humans.
monsieurpooh t1_j9nh885 wrote
Anyone who's a staunch opponent of the idea of philosophical zombies (to which I am more or less impartial) could very well be open to the idea that ChatGPT is empathetic. If prompted well enough, it can mimic an empathetic person with great realism. And as long as you don't let it forget the previous conversations it's had nor exceed its memory window, it will stay in character and remember past events.
Bakagami- t1_j9j6f40 wrote
yup and correcr me if I'm wrong, but those aren't average humans either, those are experts in their fields
Cryptizard t1_j9j6j7x wrote
You are wrong. It’s not experts. It’s randos on mechanical Turk.
Bakagami- t1_j9j7a63 wrote
rip, they should've included expert performance as well then
Artanthos t1_j9jhm3l wrote
You are setting the bar as anything less than perfect is failure.
By that standard, most humans would fail. And most experts are only going to be an expert in one field, not every field, so they would also fail by your standards.
Bakagami- t1_j9jid4u wrote
Wtf are you talking about. It's a benchmark, it's to compare performance. I'm not setting any bar, and I'm not expecting it to beat human experts immediately.
SgathTriallair t1_j9knp1a wrote
Agreed. Stage one was "cogent", stage two was "as good as a human", stage three is "better than all humans". We have already passed stage 2 which could be called AGI. We will soon hit stage 3 which is ASI.
jeegte12 t1_j9mocmt wrote
we are a million miles away from AGI.
Electronic-Wonder-77 t1_j9kvuz5 wrote
hey buddy, you might want to check this link -> Dunning-Kruger effect
SgathTriallair t1_j9kwlty wrote
Is this implying that I don't know anything about AI or that the average person is not knowledge enough to be useful?
Cryptizard t1_j9j80kk wrote
But then they wouldn’t be able to say that the AI beats them and it wouldn’t be as flashy of a publication. Don’t you know how academia works?
Bakagami- t1_j9j8djw wrote
No. I haven't seen anyone talking about it because it beat humans, it was always about it beating GPT-3 with less than 1B parameters. Beating humans was just the cherry on top. The paper is "flashy" enough, including experts wouldn't change that. Many papers do include expert performance as well, it's not a stretch to expect it.
Cryptizard t1_j9j8qk5 wrote
The human performance number is not from this paper, it is from the original ScienceQA paper. They are they ones that did the benchmarking.
IluvBsissa t1_j9j7tmn wrote
Are you joking or serious ?
Cryptizard t1_j9j7x5v wrote
Serious, read the paper.
IluvBsissa t1_j9j81ht wrote
My disappointment is unmeasurable and my day is ruined.
coumineol t1_j9jdp9z wrote
Really? So the time has come where a small-scale AI model being smarter than "ordinary" humans is not impressive.
olivesforsale t1_j9jpxi4 wrote
Awe is so last December - impatience is the new mode. They teased us with the future, now we expect it ASAP!
Cryptizard t1_j9jxvg2 wrote
It's not ordinary humans, it's people on mechanical turk who are paid to do them as fast as possible and for as little money as possible. They are not motivated to actually think that hard.
coumineol t1_j9k4pf5 wrote
That's prejudice. You don't know that.
Cryptizard t1_j9ka13l wrote
No it is economics, they make less money the longer they stop and think about it.
[deleted] t1_j9jfgzp wrote
[deleted]
[deleted] t1_j9j0w0g wrote
[deleted]
Starshot84 t1_j9jne8z wrote
Only because ai isn't as morally flexible as most ppl are
rising_pho3nix t1_j9j7vs6 wrote
Can't imagine where we'll be in 10 more years of innovation..
ground__contro1 t1_j9j81ii wrote
Perhaps never having to innovate again
Atheios569 t1_j9j9hmv wrote
Yep, and where does that leave us?
GlobusGlobus t1_j9jasjc wrote
In a sex dungeon?
duboispourlhiver t1_j9jhxrd wrote
What a time to be alive
fuck_your_diploma t1_j9jnxhz wrote
[unzips]
gentleman339 t1_j9kz2zc wrote
get away from that diploma
GlobusGlobus t1_j9l14gv wrote
Underapreciated.
[deleted] t1_j9lofnh wrote
[deleted]
ground__contro1 t1_j9ja29h wrote
At the whims of unknown forces I expect
Ylsid t1_j9jar4n wrote
Unknown forces, like the Megacorp that controls the tech
Nico_ t1_j9jd8d4 wrote
If AIs can be optimzed to run on a single graphics cards there is no controlling this.
Ylsid t1_j9jeu7o wrote
I just hope stable diffusion isn't a one off
Queue_Bit t1_j9jt52q wrote
All it takes is one smart, slightly motivated person to make a free option that's "good enough"
Ylsid t1_j9jtgcg wrote
More than one. It takes a lot of skill, time and money, which are hard to come by if you aren't a megacorp. That isn't to say it can't happen, but that it's much more difficult than you may expect.
WithoutReason1729 t1_j9jx2u1 wrote
Language models seem to be a way steeper difficulty curve though. The difference between Stable Diffusion and image generators from like a few years before it is big, but the older models are still good enough to often produce viable output. But the difference between a huge language model and a large open-source one is a way bigger gap, because even getting small things wrong can lead to completely unintelligible sentences that were clearly written by a machine.
Queue_Bit t1_j9jyddi wrote
Yeah, for sure, but as technology improves it's just going to get easier and easier. And this technology is likely to get so good that to a normal person, the difference between the best and the world and "good enough for everyday life" is likely huge.
ToHallowMySleep t1_j9jvphi wrote
It already runs happily on last-gen hardware. I've been running it on my 10GB 3080.
walkarund t1_j9k92lw wrote
It doesn't even have to be last-gen. It works well on my 4gb GTX 970 with 8gb of ram, it is very impressive how optimized it is
Ylsid t1_j9jzigu wrote
Stable diffusion works on my 6gb 2060RTX, but I am quite sure GPT3 wouldn't
ToHallowMySleep t1_j9jzzar wrote
maybe a 5090. ;)
Ylsid t1_j9k00fw wrote
An a100 sure! If you got three!
rising_pho3nix t1_j9jp2rh wrote
Exactly.. endless possibilities. Something like M3GAN could be real.
Slapbox t1_j9kovoy wrote
The first superhuman AGI will likely give its creator an insurmountable lead.
ground__contro1 t1_j9jbr1p wrote
I mean, humans have lived basically our entire lives, as a species and often individually, governed by forces we couldn’t really explain at the time. This still seems different though. Seems like no turning back. But maybe that’s been true for a long time.
mindbleach t1_j9k2m0w wrote
We've already got that. What else do you have?
ground__contro1 t1_j9kqekc wrote
Oh, just, yanno, more of it
unholymanserpent t1_j9jfpjq wrote
Pets to AI
Atheios569 t1_j9jivja wrote
Was leaning towards incubator for AI, but this works too lol.
unholymanserpent t1_j9jus0e wrote
Sounds scary but idk my pets are very loved and live very cushy lives with all their needs taken care of 🤷🏽
Atheios569 t1_j9jwcy3 wrote
The furries had it right the whole time.
NNOTM t1_j9k6gw6 wrote
Just because humans (usually) treat pets well doesn't mean AIs will though - or for that matter, find any use in pets at all
unholymanserpent t1_j9kd99g wrote
You're right, but that doesn't even begin to scratch the surface of potential issues with this change of status. Screw pets, what's the point of having us around? The gap in intelligence between us and them could be like the difference between us and worms. AI having us as pets is definitely on the optimistic side of things
NNOTM t1_j9kecol wrote
Yeah, I pretty much agree
Solandri t1_j9jjr0k wrote
Best case scenario.
the_gruffalo t1_j9krspc wrote
So, The Culture then?
Throwaway__shmoe t1_j9k1llg wrote
Hopefully sleep.
JustChillDudeItsGood t1_j9jt94z wrote
Just chillin, it's all good.
scapestrat0 t1_j9jg3dl wrote
Because of AGI or 'cuz we'll be ded
perceptualdissonance t1_j9j9kmu wrote
Not in this omniverse
coumineol t1_j9jdre7 wrote
Can't imagine where we'll be in 10 more years of innovation.
sideways t1_j9jjiuq wrote
On a beach sipping strawberry daiquiri, hopefully.
kickstartmyfartt t1_j9jna6l wrote
And not a single McDonalds shake machine out of order.
skob17 t1_j9ksqkk wrote
We already have digital nomads that do this.
sprucenoose t1_j9m63h2 wrote
All of humanity compressed into the thin strip of lifeless sand comprising Earth's border between the land and salty depths, with no sustenance except a single alcoholic beverage?
gthing t1_j9kgp3c wrote
Two more papers down the line. What a time to be alive!
brettins t1_j9km9fp wrote
Hold onto your papers!
rising_pho3nix t1_j9kgu5g wrote
Yeah, absolutely.
metametamind t1_j9khf8n wrote
I had a wondering the other day: “what does thousand-year old computer code look like?” “Ten-thousand?” “Million?”
putsonshorts t1_j9kqyb5 wrote
!Remindme 10 years
RemindMeBot t1_j9kr199 wrote
I will be messaging you in 10 years on 2033-02-22 18:18:14 UTC to remind you of this link
1 OTHERS CLICKED THIS LINK to send a PM to also be reminded and to reduce spam.
^(Parent commenter can ) ^(delete this message to hide from others.)
| ^(Info) | ^(Custom) | ^(Your Reminders) | ^(Feedback) |
|---|
Anenome5 t1_j9n5alq wrote
Bam, that's the kind of thing I want to read, because that's a direct reference to singularity :)
Supersamtheredditman t1_j9nphhm wrote
Well according to some we won’t even make it 10 years
ImperishableNEET t1_ja061ve wrote
Disassembled at the molecular level for paperclip production.
turnip_burrito t1_j9j46th wrote
One author on this paper posted on Reddit here, if you're interested in their comments.
https://www.reddit.com/r/MachineLearning/comments/10svwch/comment/j79i4jj/
Apollo24_ t1_j9j6zgo wrote
Makes me wonder what it'd look like if it was as big as gpt-3
ihrvatska t1_j9jvwty wrote
Or maybe working with gpt-3. Gpt-3 could call upon it when it needed a more narrowly focused expert. Perhaps there could be a group of AI systems that work together, each having a specialty.
FaceDeer t1_j9kgcvd wrote
Perhaps you could have a specialist AI whose specialty was figuring out which other specialist AI it needs to pass the query to. If each specialist can run on home hardware that could be the way to get our Stable Diffusion moment. Constantly swapping models in memory might slow things down, but I'd be fine with "slow" in exchange for "unfettered."
skob17 t1_j9ks9jw wrote
That's an interesting approach. We do the same in audits, where the main host is QA with a broad general knowledge of all processes, but for details they call in the SMEs to show all the details of a specific topic.
[deleted] t1_j9jwu8l wrote
[deleted]
Nalmyth t1_j9k0eu2 wrote
General vs specific intelligence.
Think of when you ask your brain what is the answer to 5x5.
Did you add 5 each time or did you do a lookup, or perhaps an approximate answer?
hosseinxj0152 t1_j9l5yzv wrote
I think this is already being done. Check out Langchain on huggingFace
monsieurpooh t1_j9nhlcf wrote
And one of the AI's specialty is to build better AI's
Destiny_Knight OP t1_j9iysi7 wrote
The paper: https://arxiv.org/pdf/2302.00923.pdf
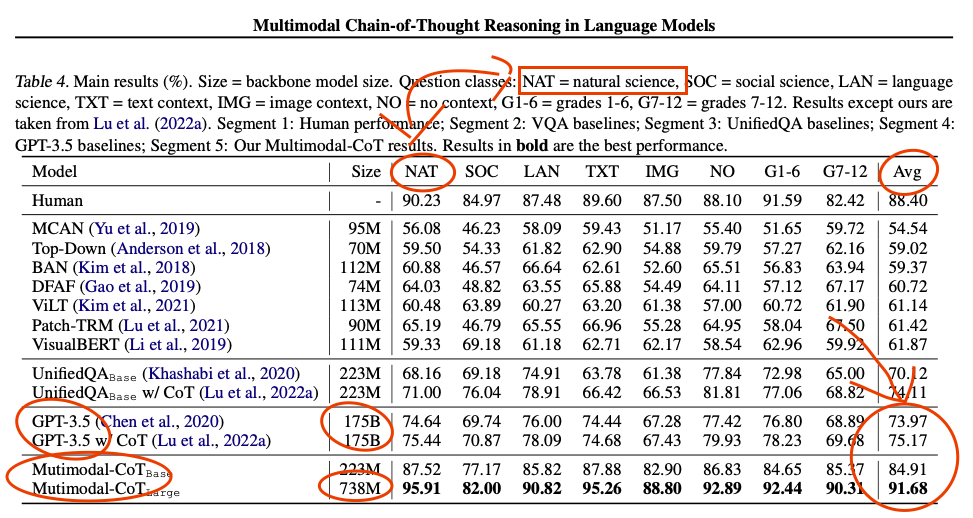
The questions: "Our method is evaluated on the ScienceQA benchmark (Lu et al., 2022a). ScienceQA is the first large-scale multimodal science question dataset that annotates the answers with de- tailed lectures and explanations. It contains 21k multimodal multiple choice questions with rich domain diversity across 3 subjects, 26 topics, 127 categories, and 379 skills. The benchmark dataset is split into training, validation, and test splits with 12726, 4241, and 4241 examples, respectively."
FirstOrderCat t1_j9ja0i4 wrote
multimodal here means questions contain pictures.
So, it is obvious gpt would underperform since it doesn't work with pictures, lol?..
EndTimer t1_j9kl706 wrote
We would have to read the study methodology to evaluate how they were testing GPT 3.5's image context.
But in this case, multimodal refers to being trained on not just text (like GPT 3.5), but also images associated with that text.
That seems to have improved their model, which requires substantially fewer parameters while scoring higher, even in text-only domains.
kermunnist t1_j9kpbtz wrote
That would make sense, having an understanding of images probably helps lead to a more intuitive grasp of physics
{kind=link}
FirstOrderCat t1_j9krjxb wrote
>which requires substantially fewer parameters while scoring higher, even in text-only domains.
Which tests in paper refer on text-only domains?
EndTimer t1_j9l1xxj wrote
Presumably, TXT (text context). LAN (language sciences) are unlikely to have many images in their multiple choice questions. The other science domains and G1-12 probably have majority text questions.
FirstOrderCat t1_j9l4bho wrote
What is IMG for GPT then there?
How come GPT performed better without seeing context compared to seeing text context?..
EndTimer t1_j9l4tc6 wrote
I don't know. It's going to be in the methodology of the paper, which neither of us have read.
FirstOrderCat t1_j9l8xn9 wrote
Yes, and then reproduce results from both papers, check the code to see nothing creative happens in datasets or during training, and there are much more claims in the academia than one has time to verify.
iamascii t1_j9o2v76 wrote
They used the captions instead of the images. The captions are pretty descriptive imho.
FirstOrderCat t1_j9p55p9 wrote
It still doesn't answer second question.
duffmanhb t1_j9jps75 wrote
So basically it's fine tuned for this specific topic, where GPT is large because it's a general dataset for multidomain use.
[deleted] t1_j9jlyhh wrote
[deleted]
Spire_Citron t1_j9j7gvn wrote
This is interesting because the questions seem to be reasoning based, which is much more impressive than some of the other tests AI have done well at that are more based on knowing a lot of information, something you'd expect a LLM to excel at beyond the abilities of a typical human.
turnip_burrito t1_j9j8dmm wrote
One critique I saw in another thread is that this was "fine-tuned to hell and back" compared to GPT-3, which could explain some of the increased performance, so take that as you will.
Spire_Citron t1_j9j9n46 wrote
Fine-tuned towards taking these sorts of tests, or just more optimised in general?
duboispourlhiver t1_j9ji6qe wrote
Yes, the risk is to be over fitted for this test. I've read that too about that paper but haven't taken the time to make my own opinion. I think it's impossible to judge if this benchmark is telling or not about the model's quality without studying this for hours
Spire_Citron t1_j9lcgc9 wrote
If it was specifically taught to do this test, it is much less impressive because it probably means it won't have that level of intuition and understanding with other tasks.
monsieurpooh t1_j9ni0aa wrote
I'm curious how the authors made sure to prevent overfitting. I guess there's always the risk they did, which is why they have those AI competitions where they completely withhold questions from the public until the test is run. Curious to see its performance in those
Borrowedshorts t1_j9kcmhm wrote
Humans finetune to the test as well.
dwarfarchist9001 t1_j9kpzs8 wrote
Humans don't suffer from overfitting if they train on the same data too much.
skob17 t1_j9kt3k1 wrote
Oh they absolutely do. If the test questions have a slightly different approach, many of the hard memory learning students fail.
Borrowedshorts t1_j9ldhl5 wrote
Yes they actually do.
pinkballodestruction t1_j9m407a wrote
I sure as hell do
Lawjarp2 t1_j9jdxur wrote
It's multiple choice, choosing among 4 options is easier because you just have to consider the 4 possibilities and answer is among the 4 possibilities. But most conversations are open ended with possibilities branching out to insane levels.
Borrowedshorts t1_j9kao68 wrote
Why is it recommended to study 1.5 months for Series 7 if it's just a multiple choice test?
Lawjarp2 t1_j9lhw2e wrote
Because you are not an llm
VeganPizzaPie t1_j9kjuth wrote
But if you have to reason out the correct answer, and do that over and over again, it doesn't matter if there are 4 options or 1000. Think about it. The bar exam and other post graduate tests have multiple choice. You think anyone could pass those? Why do they take years of study?
Lawjarp2 t1_j9liaa5 wrote
No. Once an LLM gets a keyword a lot of related stuff will come up in probabilities. Also you can go backwards on reasoning. This makes it easier for an LLM to answer if trained for this exact scenario.
Elven77AI t1_j9j97e2 wrote
Their paper: https://arxiv.org/abs/2302.00923
hylianovershield t1_j9jd6x3 wrote
Could someone explain the significance of this to a normal person? 🤔
[deleted] t1_j9k06tz wrote
[deleted]
RavenWolf1 t1_j9k09tz wrote
I'm asking this too.
redpnd t1_j9je11m wrote
Not hard for a multimodal model to outperform a text only model on multimodal tasks..
Although still impressive, imagine what a scaled up version will be able to accomplish!
Akimbo333 t1_j9jfw9i wrote
Oh yeah I agree!!!
IluvBsissa t1_j9j8ubb wrote
I don't get it. Why are they comparing their model's performance to regular humans and not experts, like every other papers ? Does it mean these tests are "average difficulty" ? I read somewhere that GPT3.5 had a 55.5% score on MMLU, while PalM was at 75 and human experts 88.8. How would this CoT model perform on standards benchmarks, then ? I feel scammed rn.
ertgbnm t1_j9jgoi9 wrote
Read the questions on scienceQA. They are hot and not hot dog type questions
Yngstr t1_j9jzzbv wrote
Am I reading this wrong? Is the dataset used to train this model the same dataset used to test it? Not saying that's not a valid method, but that certainly makes it less impressive vs generalist models that can still get decent scores...
shwerkyoyoayo t1_j9k77rq wrote
Is it overfit to the questions on the test? i.e. has it seen the same quesitons in training?
Grouchy-Friend4235 t1_j9ojfjs wrote
All LLM of the ChatGPT kind are essentially trained on the test set 😉
Akimbo333 t1_j9jg1gr wrote
Yeah those multimodal capabilities are intense!
jugalator t1_j9jadh0 wrote
I think there is still a ton to learn about usefulness of the training data itself, and how we can find out what is an optimal "fit" for a LLM? Right now, the big LLM's simply have the kitchen sink thrown at them. Who's to say that will automatically outperform a leaner, high quality, data set? And again, "high quality" for us me be different to an AI?
Ohigetjokes t1_j9lh78h wrote
This reminds me of that Westworld moment where he’s talking about the frustrations trying to emulate humans, until he realized he just needs to use a lot less code (something like 18 lines).
“Turns out we’re just not that complicated.”
AustinJacob t1_j9m8vgk wrote
Considering that GPT-J can run on local hardware and it has 6B parameters this gives me great hope for the future of open-source and non-centralized ai.
Anenome5 t1_j9n56lk wrote
We learned that you can get the same result from less parameters and more training. It's a tradeoff thing, so I'm not entirely surprised. We cannot assume that GPT's approach is the most efficient one out there, if anything it's just brute force effectiveness and we should desperately hope that the same or better results can be achieved with much less hardware ultimately. And so far it appears that this is true and is the case.
NoidoDev t1_j9nelfr wrote
>same result from less parameters and more training
Thanks, good to know.
mindbleach t1_j9k3p72 wrote
More training is better and smaller networks train faster.
BasedBiochemist t1_j9khtzg wrote
I'd be interested to know what social science questions the AI was getting wrong compared to the humans.
TinyBurbz t1_j9klnc9 wrote
Wow a specialized model out preforms a generalized one?
*shocked pikachu*
DukkyDrake t1_j9mgudi wrote
This will usually be the case. A tool optimized and fit for a particular purpose will usually outperform.
[deleted] t1_j9jopcm wrote
[deleted]
alfor t1_j9kbtxf wrote
I think it’s going to get in that direction as it’s more computer efficient.
Many speciality AI mind working together like human do.
Humans also have separation in our mind: left vs rish hemisphere, cortical columns, etc.
We specialize a lot as there is not enough mental capacity in one human to cover all aspect of human knowledge.
That’s what made chatgpt even more impressive, it’s not perfect, but it cover such a wide area compared to a human.
drizel t1_j9kmtd9 wrote
In a year or two (or less even?) we'll definitely (probably) have these running locally.
[deleted] t1_j9kn1mg wrote
[deleted]
Denpol88 t1_j9l10kd wrote
Can anyone ask this search.to Bing and share with us here, please?
nillouise t1_j9lhlwo wrote
In github, I only can download the base model, is the large model private? But I think it will be more useful to me if the model is not sicence QA instead of a game player model.
Gilded-Mongoose t1_j9md754 wrote
This guy AI’s
norbertus t1_j9me8dv wrote
A lot of these models are under-trained
and seem to be forming a type of "lossy" text compression, where their ability to memorize data is both poorly understood, and accomplished using only a fraction of the information-theoretic capacity of the model design
https://arxiv.org/pdf/1802.08232.pdf
Also, as indicated in the first citation above, it turns out that the quality of large language models is more determined by the size and quality of the training set rather than the size of the model itself.
pure_coconut_water t1_j9mletn wrote
Generalization is the end goal, not memorization.
Prufrock5150_ t1_j9mn6lw wrote
Why does this feel like the next "Getting DOOM to run on a pocket-calculator" challenge lol? Because I am *here* for that.
13ass13ass t1_j9n98ui wrote
It’s fine tuned on the dataset. No big whoop
koltregaskes t1_j9nmoh3 wrote
I believe OpenAI or others have said they've concluded that parameters are less important and data is more important. So the models need more data... a lot more. And text data alone won't be enough.
oceanfr0g t1_j9jjagz wrote
Yeah but can it tell fact from fiction
sumane12 t1_j9j0pi7 wrote
My guy, correct me if I'm wrong, but doesn't it outperform humans, in everything but social sciences?...