Comments
SkaldCrypto t1_itcbcxu wrote
This is dope.
AI_Enjoyer87 t1_itbkffq wrote
When these new models get scaled things are gonna get crazy
Professional-Song216 t1_itbpwob wrote
People have no clue, we don’t even have agi yet
Kinexity t1_itbwp5m wrote
People who don't have a clue also don't have a clue about most technology. It's not that hard to figure out looking at estimates for compute of human brain that our ML models are very inefficient which is why we got so much gains currently. Current growth in ML is like Moore's Law in semiconductors in 70s - everyone knew back then that there is a lot of room to grow but you could only get there through incremental changes.
quinkmo t1_iteq961 wrote
ELI5 should be a sub pre-req
Ezekiel_W t1_itc49gy wrote
So many amazing AI papers in the last few days, amazing times.
Ok_Marionberry_9932 t1_itf1v7r wrote
Wow I have no idea 🤷♀️ what this means
NTIASAAHMLGTTUD t1_itd6jci wrote
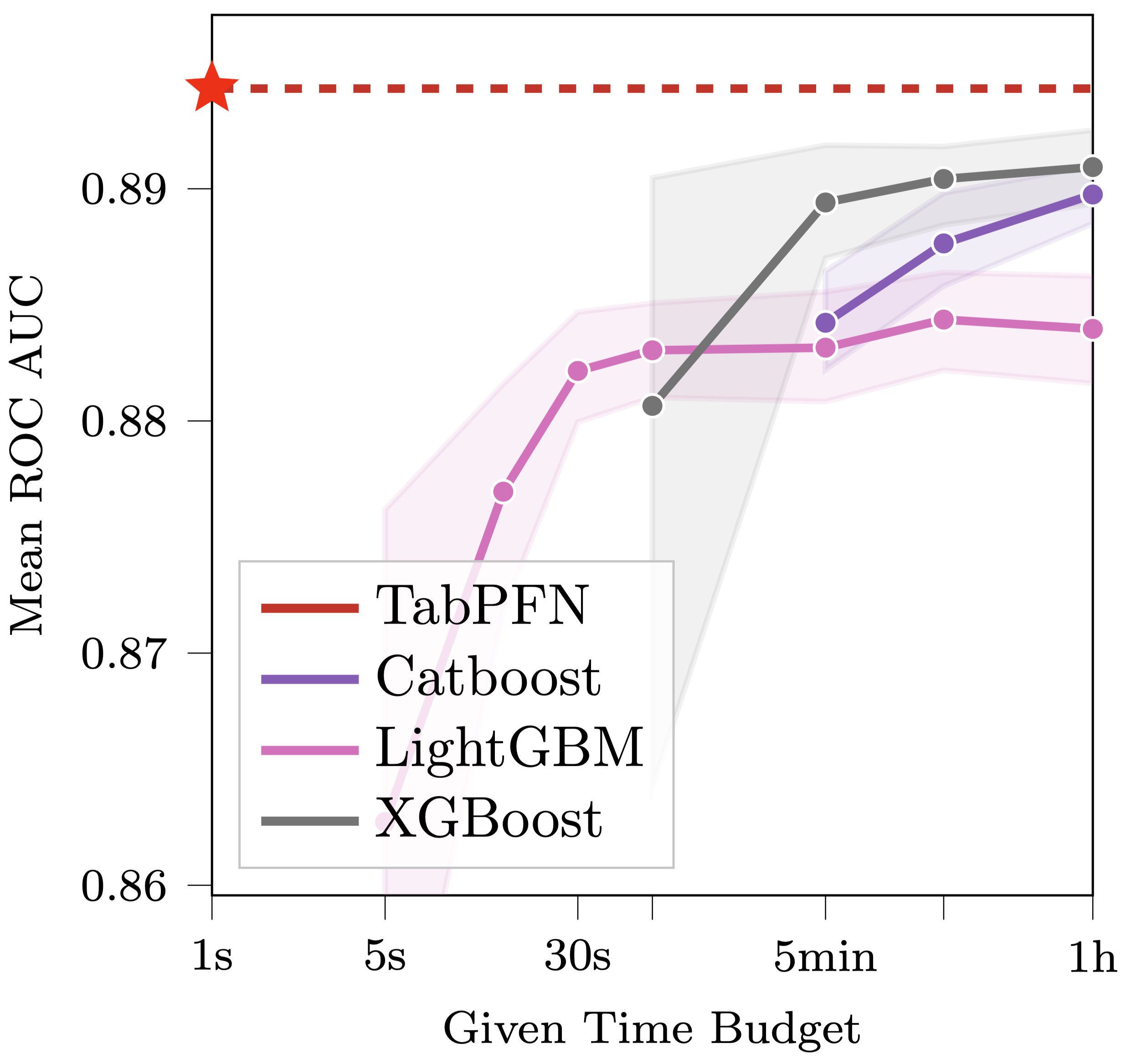
What does the Y-axis mean here, what would be considered '1' (as opposed to .88)?
Flare_Starchild t1_ite1z5a wrote
Reminds me of this: https://youtu.be/RXJKdh1KZ0w
Denpol88 OP t1_itbir0k wrote
TabPFN is radically different from previous ML methods. It is meta-learned to approximate Bayesian inference with a prior based on principles of causality and simplicity. Here‘s a qualitative comparison to some sklearn classifiers, showing very smooth uncertainty estimates
TabPFN happens to be a transformer, but this is not your usual trees vs nets battle. Given a new data set, there is no costly gradient-based training. Rather, it’s a single forward pass of a fixed network: you feed in (Xtrain, ytrain, Xtest); the network outputs p(y_test).
TabPFN is fully learned: We only specified the task (strong predictions in a single forward pass, for millions of synthetic datasets) but not how it should be solved. Still, TabPFN outperforms decades worth of manually-created algorithms. A big step up in learning to learn
Imagine the possibilities! Portable real-time ML with a single forward pass of a medium-sized neural net (25M parameters).