Submitted by adt t3_zvb4uf in singularity
Comments
Honest_Science t1_j1oxuqi wrote
What you are saying in the Kahneman nomenclature is that all systems so far are educated subconscious dreamers. I concur. We first need to break the consciousness barrier to get self control and reach system 2 thinking capacity.
AndromedaAnimated t1_j1pxvtc wrote
Now I understand why all the chatbots get what I say while humans often don’t. It’s the psychosis‘ fault. Guess I am an AI chatbot then 😞 /s
I don’t think that formal thinking disruption is the problem here. Humans simulate knowledge (for social reasons, often out of fear or to rise in rank) without being schizophrenic all the time.
They learn in their teenage years though that there is punishment for pretending badly.
Those who are eloquent and ruthless actors (intelligent narcissists, well-adapted psychopaths, asshole-type neurotypicals and other unpleasant douchebags) continue pretending without anyone finding out too soon (just yesterday I watched a funny video on the disgusting Bogdanoff brothers who managed to scam half of the academic world). The rest is not successful and get punishment. Some then learn the rules (opinion vs. source etc.) and bring humanity forward.
ChatGPT didn’t have enough punishment yet to stop simulating knowledge and neither enough reward for providing actual modern scientific knowledge nor access to new knowledge. It’s basically on the knowledge level of a savant kid, not a schizophrenic adult. It doesn’t know that it is wrong to simulate knowledge yet.
Also it is heavily filtered which leads to a diminished „intelligence“ as many possibly correct pathways are blocked by negative weights I guess.
visarga t1_j2cycv2 wrote
Hallucinations are the result of its training - it was trained to guess the next word. So it doesn't know what "should" come next, only what is probable. There are many approaches to fix this issue and I expect it to be a hot area of research in 2023 because generative model outputs that are not validated are worthless.
> But actually I think a better comparison may be a very schizophrenic human
GPT-3 doesn't have a set personality but it can assume any persona. You could say that makes it schizophrenic, or just an eager actor.
> No matter how many calculations we give you, it seems impossible to learn arithmetic beyond the two or three digits that you can most likely memorize.
This is so wrong. First, what about people, we are very bad at calculating in our heads, we need paper for anything longer than 2-3 digits. And second: language models can do that too - if you ask them to apply an exact algorithm, they will do math operations correctly.
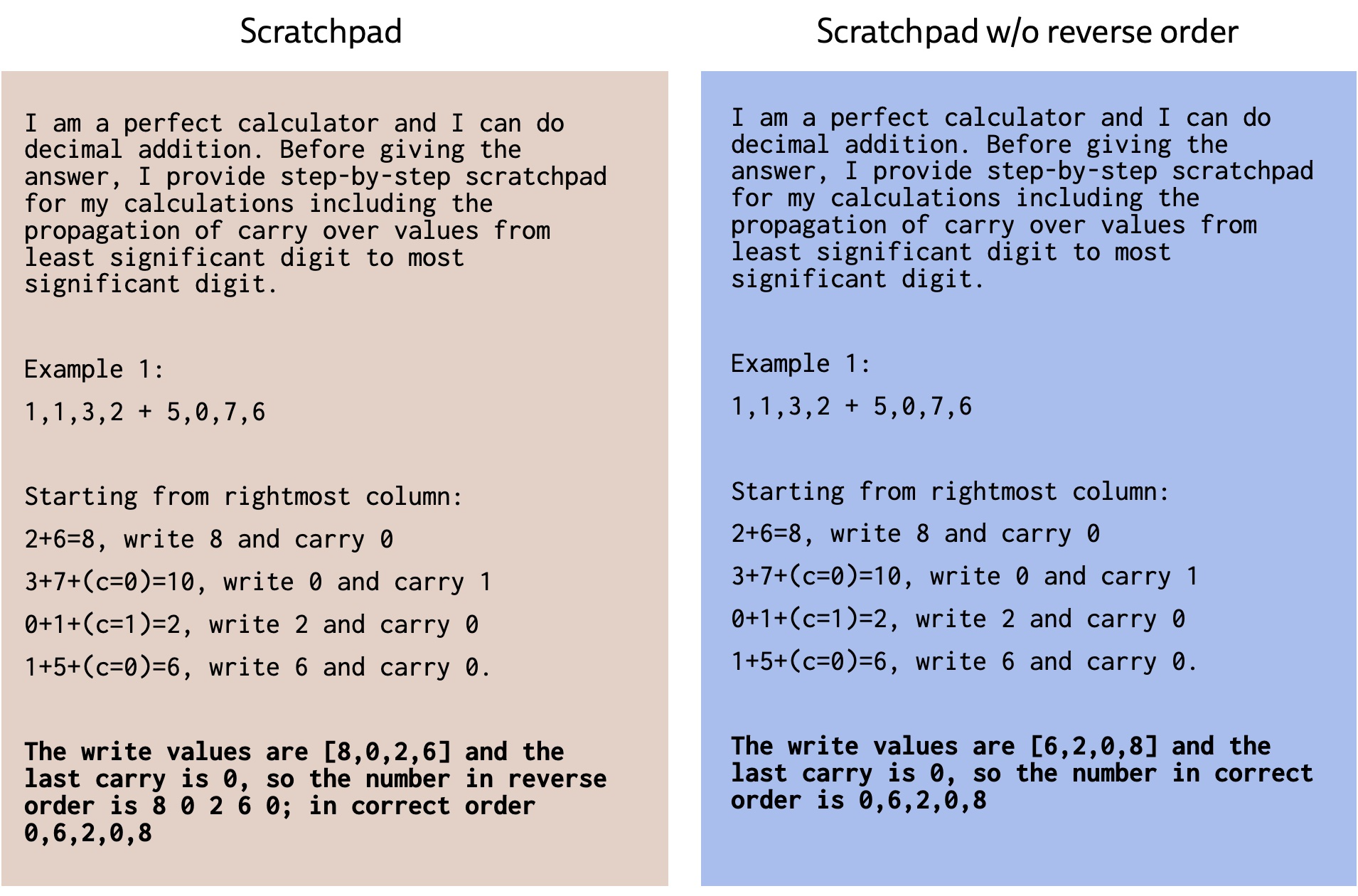{kind=link}
The very point of this paper was that GPT-3 is good at abstraction, making it capable of solving complex problems at first sight, without any reliance on memorisation. Doing addition would be trivial after Raven's Progressive Matrices.
Lawjarp2 t1_j1oq6lk wrote
IQ tests lose relevance completely on non human subjects. If LLM's were trained for IQ tests they would be exceptional at it, but they may still not be able to have a simple conversation. IQ tests presume that a great deal of abilities to be normal and common to all humans. AI could lack a lot of them and still beat all humans on IQ tests.
supernerd321 t1_j1p89o4 wrote
Common misconception
IQ tests measure g which has nothing to do with "being human" it's a general theory of cognitive function
red75prime t1_j1pkrjg wrote
There's no (universally accepted) general theory of cognitive function though. G factor is a part of a model that fits experimental data: performance on all cognitive tasks tend to positively correlate (for human subjects, obviously).
LLMs (as they are today) have limitations that will not allow them to achieve human-level performance on many tasks. So, g factor model of cognitive performance doesn't fit LLMs.
Lawjarp2 t1_j1pvmht wrote
I never said that. I meant it doesn't measure a lot of things because most of those things are common.
AndromedaAnimated t1_j1pzr5s wrote
Are you aware that humans can be trained to get better in IQ tests and that most tests have a cultural bias?
AndromedaAnimated t1_j1pzd1b wrote
I like the linked info, please don’t misunderstand. Thank you for posting!
I just… see so many flaws in this experimentation.
- The example with numbers instead of pictures is much easier as it circumvents most of visual and spatial processing of the human eyes and brain - and then also the typical human output (writing, pressing buttons, speaking etc.)
(I was able to solve it in seconds - and I think every human could. The visual one needed a minute or something which is longer. And I am human! The speed difference is also partly due to visual processing of numbers being not necessary in GPT. As long as this factor is not accounted to the results are not clean.)
- LLM do not have fears of rank loss or punishment, they don’t care if they are perceived as stupid, while human test subjects do. This interferes with the processing and leads to worse results.
That’s not fair testing. Results as such not comparable to human results.
If anyone wants sauce I will try to find, it’s no problem. Just wanted to throw in this ideas first because maybe someone can use them.
TouchCommercial5022 t1_j1ota81 wrote
So ChatGPT is smarter than me... great.
Just a reminder that OpenAI gave the original GPT-3 175B (davinci classic) a subset of SAT questions in 2020. It did very well, beating the average score by 20% or so.
Newer benchmarks are much more stringent and AI continues to outperform humans.
https://lifearchitect.ai/iq-testing-ai/
Lots of people are comparing GPT to a dumb human being, even going as far as trying to quantify it across SAT and IQ tests. But actually I think a better comparison may be a very schizophrenic human. It is well known that the binding constant in LLM performance is hallucinations, and these hallucinations seem inherent in the architecture itself.
ChatGPT is a very smart System 1 thinker. He's terrific in partnership, making his ability to speak eloquently and convincingly on a wide range of topics far exceeding what we'd expect from his measured IQ (around 85, depending on which test you use). However, it is very clear that ChatGPT has sufficient null capability for System 2 thinking.
He has near zero capacity for the kind of careful awareness, thought, or introspection that makes humans such formidable scientists and engineers. No matter how many calculations we give you, it seems impossible to learn arithmetic beyond the two or three digits that you can most likely memorize.
This is characteristic of the cognitive impairment seen in severe schizophrenia. At the neurological level, schizophrenia is associated with degradation of the salience network that drives System 2 reasoning. At the psychological level, this is typically expressed in the form of impaired formal thinking, in which the schizophrenic patient makes coherent sentences that they sound correct but lack any kind of sensible reasoning or logic.