adventuringraw
adventuringraw t1_jdxn4xh wrote
Reply to comment by affordable_firepower in The two retinas are tied/linked together in the brain. Are they tied 1:1, so that each retinal point corresponds to the same retinal point in the other eye? I.e., each retinal point from one eye shares the same binocular neuron with its counterpoint in the other eye? by ch1214ch
That reminds me of one of the diagrams from the book I got this from, I took a screenshot and posted it if you're curious.
And yeah, if the severed nerve is between your right eye and the optic chiasm, then it seems that is what happens. Half your left eye's view gets sent to one hemisphere, the other gets sent to the other, and then they get stitched together again upstream. Though I suppose if it happened when you were young enough, it could be a fair bit different... injuries when you're still in the 'critical period' can rewire in really unusual ways.
That diagram shows what's lost from severed optic tract at different points through the pipeline, thought you might think it was interesting. For every one of those, there's probably a bunch of people living that life. Sounds like you're number '1'. I think I'd actually prefer that to '2' or '3'.
Anyway, cheers... glad I could share something you found interesting. I've got ADHD, so I've got my own version of neuroscience adding to my understanding of myself, haha.
adventuringraw t1_jdw6enx wrote
Reply to comment by SkinnyJoshPeck in [D]GPT-4 might be able to tell you if it hallucinated by Cool_Abbreviations_9
You're right that there isn't a system yet that has the power of a LLM without the risk of hallucinated 'facts' woven in, but I don't think it's fair to say 'we're a long ways from that'. There's a ton of research going into different ways to approach this problem, approaches involving a tool using LLM seem likely to work even in the relatively short term (production models in the next few years, say) and that's only one approach.
I certainly don't think it's a /given/ that this problem will be solved soon, I wouldn't bet money that you're wrong about it taking a long time to get it perfect. But I also wouldn't bet money that you're right, given all the progress being made on multiple fronts towards solving this, and given the increasingly extreme focus by so many researchers and companies on this problem, and especially given the fact that solutions like this are both promising and seemingly realistic. After all, if there's a sub-system to detect that an arxiv search should be used to verify a reference before giving it, you could at least eliminate halucinated examples in this narrow area. The downside then might just be an incomplete overview of available papers, but it could eliminate any false papers from what the user sees.
All that said, this only fixes formal citations with a somewhat bespoke system. Fixing ALL inaccurate facts probably won't be possible with even dozens of 'tools'... that'll take more what you're thinking I imagine: something more like a truly general learned knowledge graph embedded as a system component. I know there's work on that too, but when THAT's fully solved, (like, TRULY solved, where modular elements of the world can be inferred from raw sensory data, and facts accumulated about their nature from interaction and written content) we'll be a lot closer to something that's arguably AGI, so... yeah. I think you're right about that being a fair ways away at least (hopefully).
adventuringraw t1_jdrnbmp wrote
Reply to comment by Fenrisvitnir in The two retinas are tied/linked together in the brain. Are they tied 1:1, so that each retinal point corresponds to the same retinal point in the other eye? I.e., each retinal point from one eye shares the same binocular neuron with its counterpoint in the other eye? by ch1214ch
Um no (we have to keep the comment chain going).
You're actually being overly dismissive of what they're saying I think. The key word they used was 'inspired'. I tried to dig up the origin of convolutional image kernels, and while I couldn't find much in five minutes of digging, I'm sure you're right, that they predate deep learning certainly, and possibly even digital computing entirely given that their historical origin was probably in signal processing.
Their comment though wasn't whether or not CNNs directly imitate biology, or that the way they did it was entirely novel... They were just pointing out that biology was an inspiration for trying it this way, and that part's unambiguously true. To my knowledge, the first paper introducing the phrase 'convolutional neural network' was from Yann LeCun. This one I believe, from 1989. If you look at the references, you'll note Hubel and Wiesel's 1962 paper introducing a crude model of biological vision processing is in the references. More importantly, Fukushima, 1980 is referenced (and mentioned in the text as a direct inspiration). This 'Neocognitron' is generally accepted to be the first proto-CNN. The architecture is a bit different than we're used to, but it's where things started... And as the author puts it in the abstract:
> A neural network model for a mechanism of visual pattern recognition is proposed in this paper. The network is self-organized by "learning without a teacher", and acquires an ability to recognize stimulus patterns based on the geometrical similarity (Gestalt) of their shapes without affected by their positions. This network is given a nickname "neocognitron". After completion of self-organization, the network has a structure similar to the hierarchy model of the visual nervous system proposed by Hubel and Wiesel.
So... Yes. CNNs weren't inspired by cow vision or something... Hubel and Wiesel's most famous work involved experiments on kittens. but CNN origins are unambiguously tied into Hubel and Wiesel's work in biological visual processing, so the person you're responding to is actually the one that was right. I just noticed even, some of the papers referenced from Wikipedia that you said didn't show biological inspiration are the same ones I mentioned even, so they were the correct papers to cite.
If I may be a bit rude for my own Sunday morning amusement: 'Thanks for being interested, but there is a lot of fluffery in ML discussions.'
Seriously though, it's an interesting topic for sure, and historical image processing techniques are certainly equally important to the history of CNNs... They were the tool reached for given the biological inspiration, so in all seriousness you're not entirely wrong from another perspective, even if you're not justified in shooting down a biological inspiration.
adventuringraw t1_jdnl4sd wrote
Reply to The two retinas are tied/linked together in the brain. Are they tied 1:1, so that each retinal point corresponds to the same retinal point in the other eye? I.e., each retinal point from one eye shares the same binocular neuron with its counterpoint in the other eye? by ch1214ch
Hm... There's not a detailed answer here yet, so I guess I'll jump in.
First thing to realize: in reach retina, there's over 100 million photoreceptors, but only 1 million axons in the optic nerve. How's that work? The answer, is that it's completely accurate to say that the earliest part of visual processing is in the eye. There's 5 layers to the retina. The million ganglion cells sending the optic nerve to central command, a middle 'processing' layer with three main types of interneurons, and the actual photoreceptor cell layer (the other two layers are 'in between' layers made up of the cabling connecting these three cell body layers).
There's actually about 20 different kinds of ganglion cells, so you can look at it as there being 20 different image filters sent in to central. Some with blue/yellow contrast, others for pure luminance contrast, etc. Some of these 'views' have very tiny 'receptive fields' (the part of the retina their signal contains information for). So-called 'P' ganglions for example can have one single cone that causes them to depolarize and fire, though they all have surrounding parts/colors that inhibits firing. Each ganglion cell actually has a fairly complex 'optimal' pattern that makes them fire... Usually either 'light in the center, dark on the edges', the reverse of that, or a color version (blue light but no yellow light, for example). So even by the time the signal's leaving the eye, you're already getting various size views containing different kinds of contrast information. It should be said too, the closer to the fovea (center of the view) the smaller the receptive field gets, so the more detail you can perceive... So the 'resolution' of your view is actually not consistent even just across the eye.
Anyway. So: the optic nerve. These million axons aren't sending pixel information, they're sending 20 pictures, each with larger or smaller receptive fields depending on type and distance from the fovea, and different activation patterns they're 'looking for' to fire. This tract splits off on the way to the central switchboard (the LGN in the thalamus). For the left hemisphere of the LGN (say), you get the right eye's ear half of the view, and the left eye's nose half of the view. Opposite that for the right hemisphere.
So, the left hemisphere switchboard gets input from the right half of the visual field. But these two views don't perfectly line up... Maybe 80% of that view does, but the most peripheral part of the view only gets a signal from the outside edge, not the nose-side edge, so your peripheral vision doesn't have a binocular signal to put together in the first place.
Input from different eyes is totally separate still in this central switchboard. Each hemisphere's LGN has 6 main layers, 3 from each eye, with thin middle layers in between carrying the comparatively small amount of color information (koniocellular layers), also still separated by eye.
Among other places (pupil and eye muscle autonomic circuits in particular) this tract then gets sent to the primary visual cortex in V1, at the very back of your head. Here, it's still separated by eye. You've got these stripes running from the back to the front, with alternating left eye, right eye input. Perpendicular to that, you've got simple edge detectors going through different orientations, and mixed into all that, you've got these barrel shaped blobs of cells that respond to color information. You can see a picture of what I mean here. One 'cycle' of left eye/right eye, and 180 degrees of orientation preference for edges marks out a roughly 1mm x 1mm 'hypercolumn', that takes in input from a chunk of the retina. These hypercolumn are the basic processing unit here in V1, and they tile over the visual field. The receptive field here is larger than a single cone or rod certainly, but it's still fairly small. You can see that the same parts of the visual field are at least nearby now though, that's what those stripes are... Lined up regions from the same part of the visual field from different eyes.
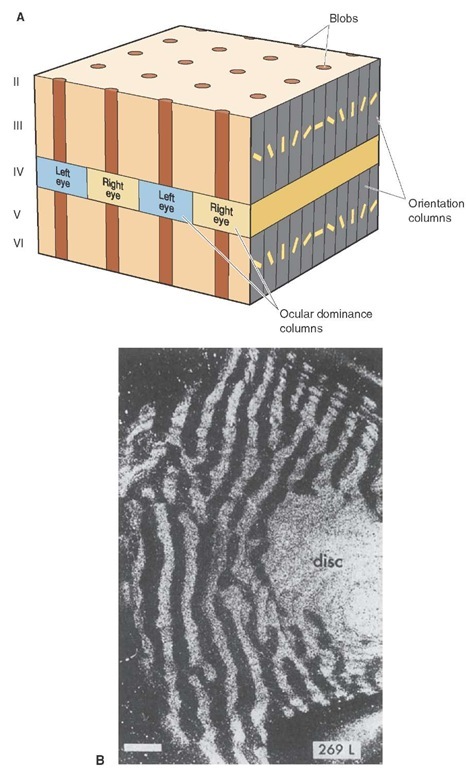{kind=link}
Once it gets to V2, the next layer of processing, this is where you start to have 'binocular integration', neurons that selectively fire based on visual input from both eyes.
As you climb up in levels, you'll see larger and larger receptive fields. By the time you get deep into the ventral visual stream (very loosely speaking, ventral stream is identifying things you're seeing, dorsal stream is for helping to guide hands and stuff for grabbing things and so on) you're seeing cells that selectively fire given complex input from anywhere in the visual field. A 'Jennifer Aniston' neuron for example that might fire anytime you're seeing her face... Or her name written, or a drawing of her, or so on, from anywhere in the visual field.
But anyway. You get the gist. The full complex view of even the early visual system is hilariously intricate, and there's no really simple description that captures all the detail. But maybe a partway answer that's close enough... Peripheral vision has no binocular component, since only one eye captures that outside edge. For the bulk of your visual field though, yes... Things get tied together eventually, but it's not until V2... After many layers of processing in the retina, LGN, and V1. By then, you're talking about receptive fields with hundreds of input photoreceptors, and you're already talking about integrating signals for fairly high level information... Direction of movement, edge orientations, color information and so on, all in separate parallel feeds, to be integrated into even more high level, abstract tracts of information with even larger receptive fields as you continue climbing up towards the dorsal (hand eye coordination) and ventral (object recognition) tracts.
Note too: every step here is more tightly interconnected than I'm describing. In particular, there's 10x connections coming BACKWARDS from downstream than there are coming in from upstream towards the retina, so you probably do have some binocular signal affecting neuron firing even before you get to the binocular integration part in V2. Those incredibly numerous backpropagating connections aren't well understood, but it does definitely complicate the question of where you can start pointing to neurons influenced by input from both eyes in the same part of the visual field.
So anyway... There you go, haha. This is largely cobbled together from Kandel's 'principles of Neuroscience, 6th edition', there's a half dozen chapters in the low 20's going through how the brain processes visual information in pretty heavy detail.
adventuringraw t1_jddte0k wrote
No one else mentioned this, so I figured I'd add that there's also much more exotic research going into low-power techniques that could match what we're seeing with modern LLMs. One of the most interesting areas to me personally, is that there's been recent progress in spiking neural networks, an approach much more inspired by biological intelligence. The idea, instead of continuous parameters sending vectors between layers, you've got spiking neurons sending sparse digital signals. Progress historically has been kind of stalled out since they're so hard to train, but there's been some big movement just this month actually, with spikeGPT. They basically figured out how to leverage normal deep learning training. That along with a few other tricks got something with comparable performance to an equivalently sized DNN, with 22x reduced power consumption.
The real promise of SNNs though, in theory you could develop large scale specialized 'neuromorphic' hardware... what GPUs and TPUs are for traditional DNNs, meant to optimally run SNNs. A chip like that could end up being a cornerstone of efficient ML, if things end up working out that way, and who knows? Maybe it'd even open the door to tighter coupling and progress between ML and neuroscience.
There's plenty of other things being researched too of course, I'm nowhere near knowledgeable enough to give a proper overview, but it's a pretty vast space once you start looking at more exotic research efforts. I'm sure carbon nanotube or superconductor based computing breakthroughs would massively change the equation for example. 20 years from now, we might find ourselves in a completely new paradigm... that'd be pretty cool.
adventuringraw t1_j9ll3fp wrote
Reply to comment by relevantmeemayhere in [D] "Deep learning is the only thing that currently works at scale" by GraciousReformer
I can see how the quote could be made slightly more accurate. In particular, tabular data in general is still better tackled with something like XGBoost instead of deep learning, so deep learning certainly hasn't turned everything into a nail for one universal hammer yet.
adventuringraw t1_j9in5sj wrote
Reply to comment by relevantmeemayhere in [D] "Deep learning is the only thing that currently works at scale" by GraciousReformer
I mean... the statement specifically uses the phrase 'arbitrary functions'. GLMs are a great tool in the toolbox, but the function family it optimizes over is very far from 'arbitrary'.
I think the statement's mostly meaning 'find very nonlinear functions of interest when dealing with very large numbers of samples from very high dimensional sample spaces'. GLM's are used in every scientific field, but certainly not for every application. Some form of deep learning really is the only game in town still for certain kinds of problems at least.
adventuringraw t1_j1abuxl wrote
Reply to comment by ClapAlongChorus in How do fusion scientists expect to produce enough Tritium to sustain D-T fusion (see text)? by DanTheTerrible
There's been recent advances with MOF filters that energetically favors Lithium going through, kind of like ion channels in cells. It drastically decreases time and water cost in filtering out Lithium, and I guess it's being tested at scale now. It certainly won't solve Lithium supply constraints, but stuff like that's cool to look at... advances in one area of tech research potentially facilitating progress in others. It'll be interesting to see how things change over the next decade.
adventuringraw t1_ixic2a7 wrote
Reply to comment by LtCmdrData in [D] Schmidhuber: LeCun's "5 best ideas 2012-22” are mostly from my lab, and older by RobbinDeBank
My favorite response here.
adventuringraw t1_jdxpfd3 wrote
Reply to comment by affordable_firepower in The two retinas are tied/linked together in the brain. Are they tied 1:1, so that each retinal point corresponds to the same retinal point in the other eye? I.e., each retinal point from one eye shares the same binocular neuron with its counterpoint in the other eye? by ch1214ch
Interesting, yeah. I bet that'd be an interesting thing to find out about even, maybe eventually brain scan technology will be cheap and powerful enough that you could look into it for a lark:).
That book mentioned that approximately 50% of the brain (or 50% of the cortex at least?) Is dedicated to vision, and there's evidence I guess for tissue that'd normally take on one function to end up doing something else if the normal input feed's down for some reason. With only half the visual input coming in when you were that young, seems like that's a lot of computational hardware that's freed up for something else. Maybe you've got some only vaguely noticed superpower you'd be surprised other people don't have, who knows?
Edit: one last thing you might find interesting. Elsewhere in this thread actually, there was a discussion about biological inspiration behind convolutional neural networks from the field of machine learning and artificial intelligence. The inspiration was from Hubel and Wiesel, two really foundational Neuroscience researchers in the late 1950's and 1960's. They won the Nobel prize for their work, one critical experiment of which involved keeping one eye of a kitten closed and seeing how it changed their development. I don't know the details of their findings, but given the historical significance of that research, I bet your case actually has a lot of understanding behind it. Just wondering out loud more than sharing anything specific, but interesting that Hubel and Wiesel more or less came up in two comment threads here.