programmerChilli
programmerChilli t1_jcny4qx wrote
Reply to comment by royalemate357 in [D] PyTorch 2.0 Native Flash Attention 32k Context Window by super_deap
We currently officially support Cuda and CPU, although in principle it could be used for other backends too.
programmerChilli t1_jci4fyx wrote
Reply to comment by logophobia in [N] PyTorch 2.0: Our next generation release that is faster, more Pythonic and Dynamic as ever by [deleted]
I've actually had pretty good success on using torch.compile for some of the stuff that KeOps works well for!
programmerChilli t1_jcdykn2 wrote
Reply to comment by Philpax in [N] PyTorch 2.0: Our next generation release that is faster, more Pythonic and Dynamic as ever by [deleted]
The segregation is that the "ML logic" is moving into Python, but you can still export the model to C++.
programmerChilli t1_j7tpwd7 wrote
Reply to comment by pommedeterresautee in [P] Get 2x Faster Transcriptions with OpenAI Whisper Large on Kernl by pommedeterresautee
Lots of things. You can see a flamegraph here: https://horace.io/img/perf_intro/flamegraph.png (taken from https://horace.io/brrr_intro.html).
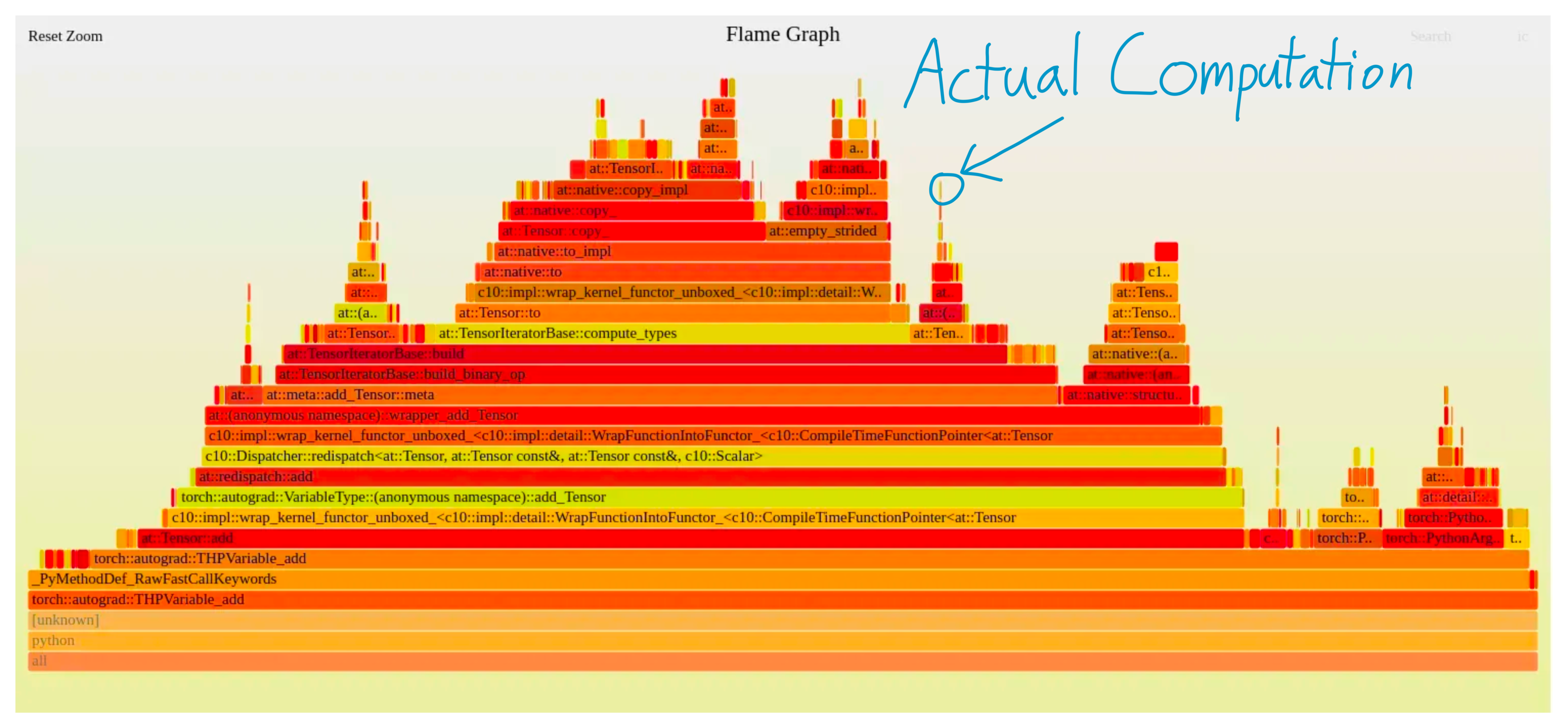{kind=link}
Dispatcher is about 1us, but there's a lot of other things that need to go on - inferring dtype, error checking, building the op, allocating output tensors, etc.
programmerChilli t1_j7toust wrote
Reply to comment by pommedeterresautee in [P] Get 2x Faster Transcriptions with OpenAI Whisper Large on Kernl by pommedeterresautee
> The Python layer brings most of the PyTorch latency.
This actually isn't true - I believe most of the per-operator latency come from C++.
programmerChilli t1_j60s9pz wrote
Reply to [P] EvoTorch 0.4.0 dropped with GPU-accelerated implementations of CMA-ES, MAP-Elites and NSGA-II. by NaturalGradient
Have you tried out PyTorch 2.0 compilation feature (i.e. torch.compile)? Might help a lot for evolutionary computation stuff.
programmerChilli t1_ixgf9cc wrote
Reply to comment by bouncyprojector in [D] Am I stupid for avoiding high level frameworks? by bigbossStrife
Generally folks refer to Keras/Lightning as “high level frameworks”. I think it’s reasonable to call Pytorch a low level framework.
programmerChilli t1_iufqn15 wrote
Reply to comment by yubozhao in [D] How to get the fastest PyTorch inference and what is the "best" model serving framework? by big_dog_2k
Well, you disclosed who you are, but that's pretty much all you did :P
The OP asked a number of questions, and you didn't really answer any of them. You didn't explain what BentoML can offer, you didn't explain how it can speed up inference, you didn't really even explain what BentoML is.
Folks will tolerate "advertising" if it comes in the form of interesting technical content. However, you basically just mentioned your company and provided no technical content, so it's just pure negative value from most people's perspective.
programmerChilli t1_itv2ckn wrote
Reply to [P] Up to 12X faster GPU inference on Bert, T5 and other transformers with OpenAI Triton kernels by pommedeterresautee
I'm somewhat surprised Inductor performs worse than cudagraphs given Inductor by default should be wrapped behind cudagraphs.
programmerChilli t1_ithnl21 wrote
Reply to comment by idrajitsc in [D] Comprehension issues with papers from non-English speakers by Confused_Electron
This site claims that it's an archaic form of "be consistent with".
programmerChilli t1_it9ujo5 wrote
Reply to comment by itsPittsoul in [D] Accurate blogs on machine learning? by likeamanyfacedgod
I thought it was pretty good :)
programmerChilli t1_is7vgbp wrote
Reply to comment by AlmightySnoo in [N] First RTX 4090 ML benchmarks by killver
I mean... it's hard to write efficient matmuls :)
But... recent developments (i.e. CuBLAS and Triton) do allow NN frameworks to write efficient matmuls, so I think you'll start seeing them being used to fuse other operators with them :)
You can already see some of that being done in projects like AITemplate.
I will note one other thing though - fusing operators with matmuls is not as big of a bottleneck in training, this optimization primarily helps in inference.
programmerChilli t1_jcnydmw wrote
Reply to comment by tripple13 in [D] PyTorch 2.0 Native Flash Attention 32k Context Window by super_deap
I think it is used in Pytorch’s nn.transformerencoder but a lot of people like implementing their own.