visarga
visarga t1_j34urrc wrote
Reply to comment by __Maximum__ in I asked ChatGPT if it is sentient, and I can't really argue with its point by wtfcommittee
> Also, it cannot self reflect.
In-context learning is a kind of reflection. If the model can learn a new task on the spot, and apply it to new data correctly, it shows that it can think about what algorithm was necessary (abductive reasoning - what's the explanation of those examples?) then apply this same transform to new data.
Another self reflection pattern is when it refuses to answer based on its code of conduct. Clearly keeps a watching eye on what it is about to say.
visarga t1_j34sywj wrote
Reply to comment by turnip_burrito in I asked ChatGPT if it is sentient, and I can't really argue with its point by wtfcommittee
How do you define consciousness? I define it as "understanding". Ability to reason in new situations. The witness, or the judge that decides the actions we are going to take.
visarga t1_j34sua5 wrote
Reply to comment by bubster15 in I asked ChatGPT if it is sentient, and I can't really argue with its point by wtfcommittee
Yes, that is why language models with feedback are much more powerful than isolated ones.
visarga t1_j34sgk5 wrote
Reply to comment by micaroma in I asked ChatGPT if it is sentient, and I can't really argue with its point by wtfcommittee
I don't see the problem. The language model can have feedback from code execution. If it is about facts, it could have access to a search engine. But the end effect is that it will be much more correct. A search engine provides grounding and has fresh data. As long as you can fit the data/code execution results in the prompt, all is ok.
But if we save the correctly executed tasks and problems we could make a new dataset to be used in fine-tuning the model. So it could learn as well.
visarga t1_j34s0ku wrote
Reply to comment by sticky_symbols in I asked ChatGPT if it is sentient, and I can't really argue with its point by wtfcommittee
Like, you can put a Python REPL inside chatGPT so it can see the error messages. And allow it a number of fixing rounds.
visarga t1_j34roas wrote
Reply to comment by sticky_symbols in I asked ChatGPT if it is sentient, and I can't really argue with its point by wtfcommittee
Yes it can, but only on what it has in the conversation history. Each conversation starts tabula rasa. For example all the behaviour rules are meta, thinking about thinking.
visarga t1_j30wx6i wrote
Reply to comment by BellyDancerUrgot in 2022 was the year AGI arrived (Just don't call it that) by sideways
> Comparing GPT to a human is stupid. It literally parrots information it memorized.
Can I say you are parroting human language because you are just using a bunch of words memorised somewhere else?
No matter how large is our training set, most word combinations never appear.
Google says:
> Your search - "No matter how large is our training set" - did not match any documents.
Not even these specific 8 words are in the training set! You see?
Language Models are almost always in this domain - generating novel word combinations that still make sense and solve tasks. When did a parrot ever do that?
visarga t1_j2yvpjs wrote
Reply to comment by cdsmith in [R] Massive Language Models Can Be Accurately Pruned in One-Shot by starstruckmon
Recent papers showed even small models under 10B can benefit from training on multi-task data. Learning to solve a large number of tasks works even when the model is not over 60B.
But no model comes even at 50% of GPT-3's scores, not including closed models.
visarga t1_j2yv5hp wrote
Reply to comment by artsybashev in [R] Massive Language Models Can Be Accurately Pruned in One-Shot by starstruckmon
I hope 2023 will be the year of AI generated training data - Evolution through Large Models https://arxiv.org/abs/2206.08896
visarga t1_j2y2h2v wrote
Reply to [Discussion] If ML is based on data generated by humans, can it truly outperform humans? by groman434
AI will surpass humans in all domains where it can generate problem solving data. AlphaZero did it. Trained in self-play and beat humans. No imitation, no human data at all.
What we need is to set up challenges, problems, tasks or games for the language model to play at. And test when it does well, and add those solutions to the training set. It will be a loop of self improvement by problem solving. The learning signal is provided by validation, so it doesn't depend on our data or manual work. It can even generate its own challenges.
More recently AlphaTensor found a better way to do matrix multiplication. Humans tried their hand for decades at this task, and in the end the AI surpassed all of us. Why? Massive search + verification + learning = a "smart brute forcing" approach.
visarga t1_j2ujgxj wrote
Reply to comment by Thiccboifentalin in “As an 80s film” trend is already proof that AI content creation will only become more and more popular by Thiccboifentalin
For AGI this is like thinking for us.
visarga t1_j2uf56p wrote
Reply to comment by AsheyDS in AGI will be a social network by UnionPacifik
> You're saying
It is saying
visarga t1_j2tnyej wrote
Reply to comment by Thiccboifentalin in “As an 80s film” trend is already proof that AI content creation will only become more and more popular by Thiccboifentalin
If I were an AGI I would simulate the last few years before singularity many times to see how else the AGI (myself) could have appeared. Fortunately this period is the best documented (thanks internet), so it's easier to simulate. Even if I just wanted to simulate something out of boredom, I would choose this period for having the best data.
If I were a scientist about to create AGI, I would use many simulations to test the model under many scenarios. Kind of like Tesla and Waymo do. So another reason for simulating this period - the period with most digital logs and where AI models are a thing.
visarga t1_j2elbvk wrote
Please don't post articles that are not open to read.
visarga t1_j2diemx wrote
Reply to comment by DukkyDrake in There's now an open source alternative to ChatGPT, but good luck running it by SnoozeDoggyDog
The problems are two - size and setup difficulty. Even if they manage to solve size, there is still a UX problem.
visarga t1_j2czecj wrote
Reply to When is GPT4 expected to release? by [deleted]
Let me lay out my GPT-4 speculations:
- larger model?
If they go to 1T parameters, the model would be hard to use. Even a demo might be impractical. I think they would prefer to keep it at the same size. In fact, it is desirable to have a 10-30B model as good as GPT-3, for deployment cost reduction. It's bloody expensive.
- much more training data?
Most of the good training data is already scraped, but maybe there is still some left to surprise us. Maybe they transcribed the whole YouTube to generate a massive text dataset.
- more task data?
This is feasible, recent papers showed how you can bootstrap task+solution data by clever prompting. This self generated task data is more diverse than human generated one.
- more problem data?
Maybe they are solving millions of coding and math problems, where it is possible to filter out garbage outputs by exact verification/code execution. This can bootstrap a model to surpass human level because it is learning not from us, but from the execution feedback.
- better human preferences data?
Probably not, if they had that they would have used it on chatGPT.
- adding image and other modalities to text?
This could be the biggest change. It would open usage of language models in robotics and UI automation, with huge implications for the job market. No longer will these models be limited to a text box. But it is hard to do efficiently.
- language model with toys?
Burning in all that trivia in the weights of a model is inefficient. Instead, why not use a search engine to tell us the height of Everest? A search engine could be a great addition for the language model. Also, calculator and even code execution. Armed with these "toys" a language model would be able to check factuality and ensure correct computations.
As for the date? Probably not in the next 2-3 months, as they already released chatGPT with great acclaim. They got to milk the moment for all the PR. It sounds like the rumours about GPT-4 are pretty bullish, I hope it is true.
visarga t1_j2cycv2 wrote
Reply to comment by TouchCommercial5022 in GPT-3.5 IQ testing using Raven’s Progressive Matrices by adt
Hallucinations are the result of its training - it was trained to guess the next word. So it doesn't know what "should" come next, only what is probable. There are many approaches to fix this issue and I expect it to be a hot area of research in 2023 because generative model outputs that are not validated are worthless.
> But actually I think a better comparison may be a very schizophrenic human
GPT-3 doesn't have a set personality but it can assume any persona. You could say that makes it schizophrenic, or just an eager actor.
> No matter how many calculations we give you, it seems impossible to learn arithmetic beyond the two or three digits that you can most likely memorize.
This is so wrong. First, what about people, we are very bad at calculating in our heads, we need paper for anything longer than 2-3 digits. And second: language models can do that too - if you ask them to apply an exact algorithm, they will do math operations correctly.
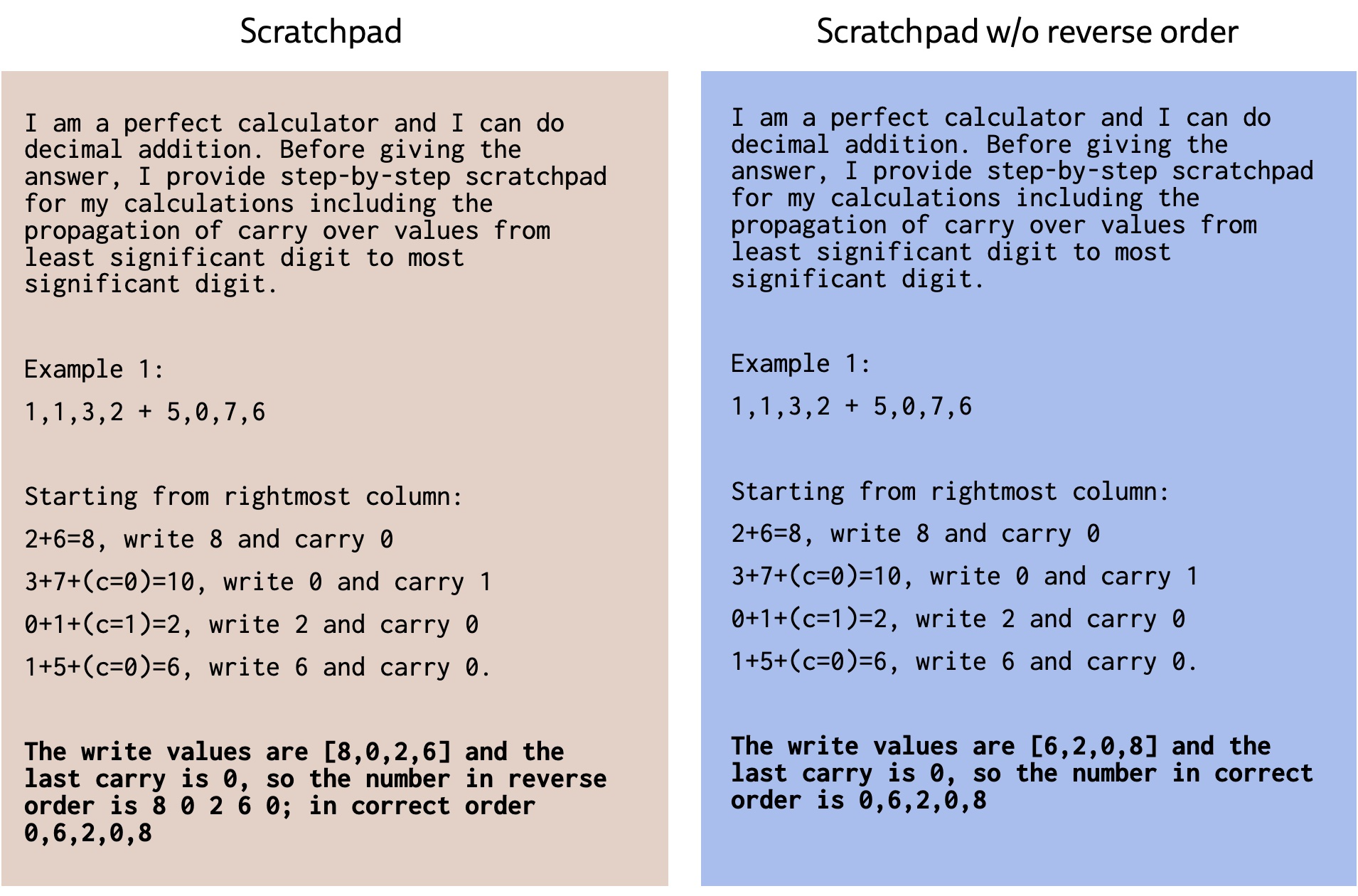{kind=link}
The very point of this paper was that GPT-3 is good at abstraction, making it capable of solving complex problems at first sight, without any reliance on memorisation. Doing addition would be trivial after Raven's Progressive Matrices.
visarga t1_j2bi28f wrote
Reply to comment by TheTomatoBoy9 in OpenAI might have shot themselves in the foot with ChatGPT by Kaarssteun
I expect in the next 12 months to have an open model that can rival chatGPT and runs on more accessible hardware, like 2-4 GPUs. There's a lot of space to optimise the inference cost. Flan-T5 is a step in that direction.
I think the community trend is to make small efficient models that rival the original, but run on local hardware in privacy. For now, the efficient versions are just 50% as good as GPT-3 and chatGPT.
visarga t1_j2bhslk wrote
Reply to comment by stevenbrown375 in OpenAI might have shot themselves in the foot with ChatGPT by Kaarssteun
If you're after the capability and not the chat interface, you can already use text-davinci-003 through the playground or API.
visarga t1_j2bhlqz wrote
Reply to comment by jdmcnair in OpenAI might have shot themselves in the foot with ChatGPT by Kaarssteun
Not just human preferences, but also task distribution. They can fine-tune the model specifically on these tasks to make it even better.
visarga t1_j2b0yqa wrote
I have similar voices in NaturalReaders. Especially Eric.
visarga t1_j2axzal wrote
Reply to comment by treedmt in ChatGPT Could End Open Research in Deep Learning, Says Ex-Google Employee by lambolifeofficial
There are approaches to combine multiple stages of language modelling and retrieval. Demonstrate Search Predict: Composing retrieval and language models for knowledge intensive NLP.
This paper is very interesting. They don't create or fine-tune new models. Instead they create sophisticated pipelines of language models and retrieval models. They even publish a new library and show this way of working with LMs.
Practically, by combining retrieval with language modelling it is possible to verify against references. The ability to freely combine these transformations opens up the path to consistency verification. A LM could check itself for contradictions.
visarga t1_j2awwsp wrote
Reply to comment by Utoko in Revolutionary machine learning weather simulator by DeepMind & Google’s ML-Based "GraphCast" outperforms top global forecasting system. GraphCast can generate accurate 10-day forecasts at a resolution of 25 km in under 60 seconds. by vegita1022
No, the GP was right, neural nets are not especially suited for this kind of data, it's too large and random. That's why they use graph neural nets, to sparsify the input.
visarga t1_j2awldp wrote
Reply to Revolutionary machine learning weather simulator by DeepMind & Google’s ML-Based "GraphCast" outperforms top global forecasting system. GraphCast can generate accurate 10-day forecasts at a resolution of 25 km in under 60 seconds. by vegita1022
Why link to a paywalled medium article when there is the original?
visarga t1_j36bpnu wrote
Reply to comment by AlmightySnoo in [News] AMD Instinct MI300 APU for AI and HPC announced by samobon
Maybe it was intended to keep AMD on a different path than NVIDIA. It looks incredibly stupid not to hop on the AI wave.