visarga
visarga t1_ixiec41 wrote
Reply to comment by purple_hamster66 in When they make AGI, how long will they be able to keep it a secret? by razorbeamz
The main idea here is to use
-
a method to generate solution candidates - a language model
-
a method to filter/rank the candidates - ensemble of predictions or running a test (such as in testing code)
Minerva - https://ai.googleblog.com/2022/06/minerva-solving-quantitative-reasoning.html
AlphaCode
- https://www.deepmind.com/publications/competition-level-code-generation-using-deep-language-models (above average competitive programmers)
FLAN-PaLM - https://paperswithcode.com/paper/scaling-instruction-finetuned-language-models (top score on MMLU math problems)
DiVeRSe - https://paperswithcode.com/paper/on-the-advance-of-making-language-models (top score MetaMath)
visarga t1_ixh56gc wrote
Reply to Meta AI presents CICERO — the first AI to achieve human-level performance in Diplomacy, a strategy game which requires building trust, negotiation and cooperation. by Kaarssteun
From AlphaGo to Diplomacy in just 6 years! They were saying the Go board is simple, everything visible and has a short list of possible actions, while real world has uncertainty, complexity and much more diversified actions. But Diplomacy has all that.
visarga t1_ixggjfm wrote
Reply to [R] Getting GPT-3 quality with a model 1000x smaller via distillation plus Snorkel by bradenjh
> Has anyone else tried something similar?
Trying it right now, but instead of using GPT-3 I am splitting the data like cross-validation and training ensembles of models. Ensemble disagreement =~ error rate.
visarga t1_ixfdcaj wrote
Reply to comment by TFenrir in When they make AGI, how long will they be able to keep it a secret? by razorbeamz
I don't believe that, OpenAI and a slew of other companies can make a buck on cutting edge language/image models.
My problem with Google is that it often fails to understand the semantic of my queries replying with other content that is totally unrelated, so I don't believe in their deployed AI. It's dumb as the night. They might have shiny AI in the labs but the product is painfully bad. And their research teams almost always block the release of the models and don't even have demos. What's the point in admiring such a bunch? Where's the access to PaLM, Imagen, Flamingo, and other toys they dangled in front of us?
Given this situation I don't think they really align themselves with AI advancement, instead they align with short term profit making, which is to be expected. Am I making conspiracies or just saying what we all know - companies work for profits, not for art.
visarga t1_ixd6ygt wrote
Reply to comment by TFenrir in When they make AGI, how long will they be able to keep it a secret? by razorbeamz
> I have absolutely no idea what you mean by "1-2 years late", in what way are they late?
GPT-3 was published in May 2020, PaLM in Apr 2022. There were a few other models in-between but they were not on the same level.
Dall-E was published in Jan 2021, Google's Imagen is from May 2022.
> Google is already looking at integrating language models
Yes, they are. But do a search and you'll see how poor the results are in reality. They don't want us to actually find what we're looking for, not immediately. They stand to lose money.
Look at Google Assistant - the language models can write convincing prose and handle long dialogues, in the meantime Assistant defaults to web search 90% of the questions and can't hold much context. Why? Because Assistant is cutting into their profits.
I think Google wants to monopolise research but quietly delay its deployment as much as possible. So their researchers are happy and don't make competing products, while we are happy waiting for upgrades.
visarga t1_ixd4ks5 wrote
Reply to [P] BetterTransformer: PyTorch-native free-lunch speedups for Transformer-based models by fxmarty
Does it include Flash Attention?
visarga t1_ixbka8a wrote
Reply to comment by TFenrir in When they make AGI, how long will they be able to keep it a secret? by razorbeamz
They have a bunch of good models but they are 1-2 years late.
Also Google is standing to lose from the next wave of AI, from a business-wise perspective. The writing on the wall is that traditional search is on its way out, now more advanced AI can do direct question answering. This means ads won't get displayed. They are dragging their feet for this reason, this is my theory. The days of good old web search are limited.
But hey, you could say they might ask the language model to shill for various products. True, but language models can also run on the edge, so we could have our own models that listen to our priorities and wishes.
That was not something possible to do with web search, but accessible through AI. The moral of the story is that Google's centralised system is getting eroded and they are losing control and ad impressions.
visarga t1_ixa9md9 wrote
Reply to comment by purple_hamster66 in When they make AGI, how long will they be able to keep it a secret? by razorbeamz
> They even used a Genetic Evolution algorithm to find new proofs, and got a few that no human had thought of before
This shows you haven't been following the state of the art in theorem proving.
> AGI is an illusion, although a very good one that’s useful.
Hahaha. Yes, enjoy your moment until it comes.
visarga t1_ixa8oko wrote
Reply to comment by Drunken_F00l in When they make AGI, how long will they be able to keep it a secret? by razorbeamz
Look, you can prompt GPT-3 to tell you this kind of advice if that's your thing. It's pretty competent at generating heaps of text like you wrote.
You can ask it to take any position on any topic, the perspective of anyone you want, and it will happily oblige. It's not one personality but a distribution of personalities, and its message is not "The Message of the AI" but just a random sample from a distribution.
visarga t1_ixa7bi6 wrote
Reply to comment by entanglemententropy in When they make AGI, how long will they be able to keep it a secret? by razorbeamz
By the moment we have AGI the world will be full of proto-AGI and advanced tool AIs. The AGI won't simply win the market, it has to compete with specialised tools.
visarga t1_ixa6sej wrote
Reply to comment by TFenrir in When they make AGI, how long will they be able to keep it a secret? by razorbeamz
Probably OpenAI. Google's been playing catchup as of late. I bet their best people from 2018 left long ago. For example almost all of the original inventors of the transformer left. This period of layoffs and resignations is seeding many startups.
visarga t1_ix7gaej wrote
visarga t1_ix2wyw6 wrote
Reply to comment by massimosclaw2 in [D] Are researchers attempting to solve the ‘omnipotence’ requirement problem in LLMs? by [deleted]
There is also prompt-tuning that will fine-tune only a few token embeddings keeping the model itself frozen. This changes the problem from finding that elusive prompt to finding a few labeled examples + fine-tuning the prompt.
Another approach is to use a LLM to generate prompts and filter them by evaluation. This has also been used to generate step by step reasoning traces for datasets that only have input-output pairs. Then train another model on the examples + chain of thought for a big jump in accuracy.
There's a relevant paper here: Large Language Models Can Self-Improve. They find that
> fine-tuning on reasoning is critical for self-improvement
I would add that sometimes you can evaluate a result, for example when generating math or code. Then you can learn from the validated outputs of the network. Basically what was used for AlphaZero to reach super-human level without supervision, but requires a kind of simulator - a game engine, a python interpreter, or a symbolic math engine.
visarga t1_ix2vuys wrote
Reply to [D] Are researchers attempting to solve the ‘omnipotence’ requirement problem in LLMs? by [deleted]
You mean like this? You just prepend "The following is a conversation with [a very intelligent AI | a human expert]". In image generation the trick is to add artist names to the prompt "in the style of X and Y", also called "style phrases" or "vitamin phrases".
Dall-E 2 was tweaked in a similar way to be more diverse when asking for a photo of a CEO, or other job, they would add various race and gender keywords. People were generally upset about having their prompts modified. But prepending the modifier on top by default might be useful in some cases.
If you want to extract a specific style or ability more precisely from a model you can fine-tune it on a small dataset, probably <1000 examples. This is easy to do using the cloud APIs, but not as easy as prompting.
visarga t1_ix0ji8d wrote
Reply to comment by Kolinnor in Why Meta’s latest large language model survived only three days online by nick7566
> it was utter trash and excessively arrogant
Galactica is a great model for citation retrieval. It has innovations in citation learning and beats all other systems. Finding good citations is a time consuming task when writing papers.
It also has a so called <work> token that triggers additional resources such as a calculator or Python interpreter. This is potentially very powerful, combining neural and symbolic reasoning.
Another interesting finding from this paper is that a smaller, very high quality dataset can replace a much larger, noisy dataset. So there's a trade-off here between quality and quantity, it's not sure which direction has the most payoff.
I'd say the paper was targeted for critique because it comes from Yann LeCunn's AI institute. Yann has some enemies on Twitter since a few years ago. They don't forget or forgive. There's a good video on this topic by Yannic Kilcher.
And by the way, the demo still lives on HuggingFace: https://huggingface.co/spaces/lewtun/galactica-demo
visarga t1_iwwdkai wrote
Reply to comment by Rodny_ in [P]Modern open-source OCR capabilities and which model to choose by Rodny_
Because it's a lucrative AI API for all the big players. Selling OCR for documents.
visarga OP t1_iwutuf1 wrote
This is good reading, will synthesize where we are and what's coming soon.
I'd like to add that training LLMs on massive video datasets like YouTube will improve their procedural knowledge - how to do things step by step, with applications in robotics and software automation. We have seen large models on text and images, but video adds the time dimension, there is audio and speech as well. Very multi-modal.
Action driven models are going to replace more and more human work, much more than the tool-AIs we have today. They will cause big changes in the job market.
visarga t1_iwlxe03 wrote
Reply to comment by snairgit in [P] Thoughts on representing a Real world data by snairgit
About representing your features - I would not feed float values directly to a neural net. I think you either need to discretise the values or to embed them like absolute positional embeddings in transformers. Or try using a SIREN on your float values directly.
visarga t1_iwkbncq wrote
Reply to comment by 94746382926 in Cerebras Builds Its Own (1 Exaflop) AI Supercomputer - Andromeda - in just 3 days by Dr_Singularity
One Cerebras chip is about 100 top GPUs in speed but in memory it only handles 20B weights, they mention GPT-NeoX 20B. They need to stack 10 of these to train GPT-3.
visarga t1_iwkaawn wrote
Reply to comment by Evil_Patriarch in A typical thought process by Kaarssteun
Never saw herbivore men term tied to crowding. Is that the reason? Crowding?
visarga t1_iwk9y88 wrote
Reply to comment by MGorak in A typical thought process by Kaarssteun
> Kids take a lot of resources to raise and it keeps getting worse.
I want to make a parallel here - automation is taking jobs away, but our expectations and desires outgrow it so, even after 100 years of fast tech progress we still have low unemployment rate. I don't think AI will mean idle humans with nothing to do and no motivation to try. We are unsatiated desire machines.
visarga t1_iwk988q wrote
Reply to comment by UnrulyNemesis in A typical thought process by Kaarssteun
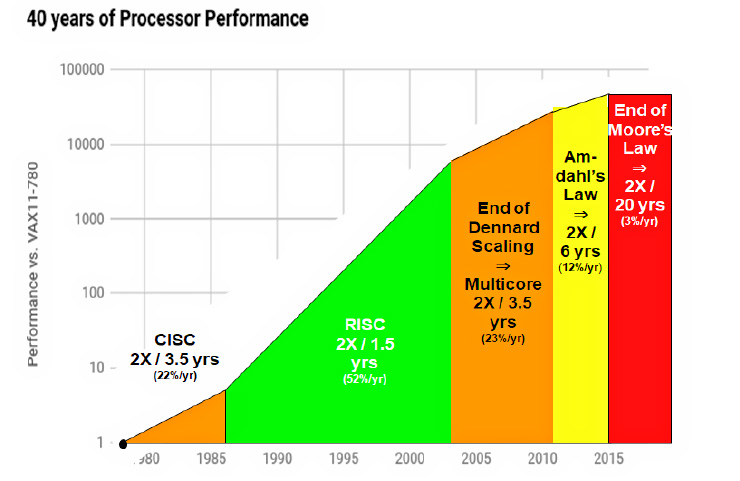
Moore's law slowed down from 2x every 1.5 years to 2x every 20 years. We're already 7 years deep into this stage. Because of that AI research is expensive, state of the art models are inaccessible to normal researchers, and democratic access to AI is threatened. Building a state of the art fab is so necessary and difficult that it becomes a national security issue. I think there's room for concern, even while acknowledging the fast progress.
{kind=link}
visarga t1_iwk7vbl wrote
Reply to comment by gynoidgearhead in A typical thought process by Kaarssteun
Exploration is necessary but risk is expensive. If you want innovation you got to have rewards or some other forcing factor, such as imminent danger.
visarga t1_iwh8n84 wrote
Reply to comment by -ZeroRelevance- in Ai art is a mixed bag by Nintell
I would first collect examples of frequent issues: double heads, noodle hands, deformities. These are the negative examples. I would collect positive examples from the training set because those images are supposedly normal, but match them as well as possible to the negative examples with cosine similarity. Train a rejection model.
To generate prompts I would finetune gpt-2 on a large collection of prompts crawled from the net. Put the prompts into SD, reject deformed images. Rank the images with an image quality model (probably easy to find), keep only the high quality ones.
You can generate as many images as you like. They would be un-copyrightable because they have been generated end-to-end without human supervision. So just great for making a huge training set for AI art.
You could also replace all known artist names with semantic hashes to keep the capability of selecting styles without needing to name anyone. We would have style codes or style embeddings instead of artist names.
visarga t1_ixig5d7 wrote
Reply to comment by Frumpagumpus in what does this sub think of Elon Musk by [deleted]
> honestly the key technical insights in the paper probably come from one or two people
The winning tickets in a lottery are just a few, but beforehand we don't know which ones. Hindsight is 20:20